
AICE 자격증 학습 블로그 챌린지 (4일차)
블로그에 올리는 건 4일차지만, 내용 자체는 제공된 3일차 스터디 플랜의 뒷부분이다.
6~9. AI 모델링하기
- AI 모델링 : 데이터에 적합한 AI 알고리즘 선택 / 준비된 데이터로 모델 학습 / 평가 및 개선
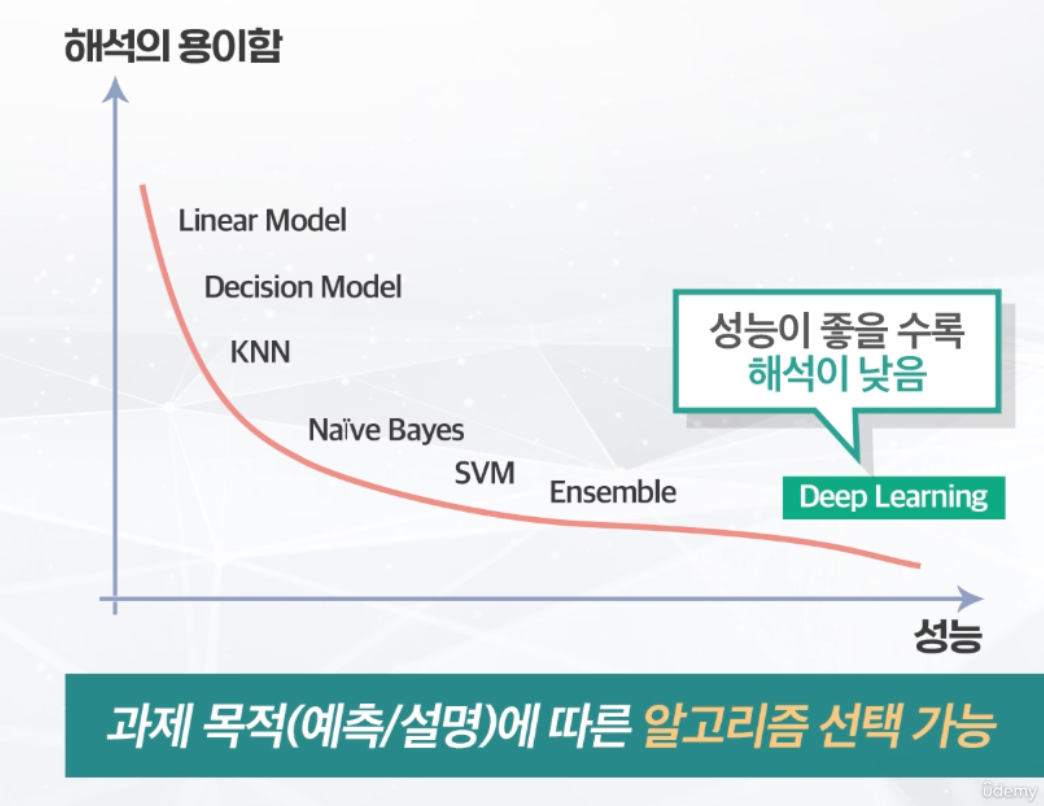
[알고리즘 선택]
- 타겟 변수 : 분류 데이터 / 수치 예측(회귀) 데이터
- 과제의 목적 : 설명 / 예측
-- 설명 : 결과의 원인 분석, 결과에 영향을 주는 변수(컬럼) 분석
-- 예측 : 결과 자체가 중요한 경우, 미래 상황에 대비할 필요가 있는 경우
(타겟 변수 특성과 과제의 목적에 따라 알고리즘 범위를 좁힐 수 있음)
[모델 학습]
- 손실함수의 값을 최소화하는 방식으로 가중치를 업데이트
-- 손실함수(Loss function) : 신경망 학습의 목적함수로 출력값(예측)과 정답(실제)의 차이를 계산, 값이 작을수록 더 잘 예측
-- 가중치(Weight) : 출력값과 정답을 비교해 오차를 최소화하기 위해 임의의 값을 조금씩 조정하는 파라미터
- 훈련(Train) 데이터와 평가(Test) 데이터 분리 (모델 학습 전 해야함)
-- 수집한 데이터를 대상으로 한 것만이 아닌 범용적인 데이터에서 잘 예측하기 위함
-- 분리하지 않고 공유 시, 모델의 객관적 평가가 불가능(모델이 일반적인 규칙을 찾는 것이 아닌 답의 지협적 특성을 외우기 때문)
-- 평가를 위해 모델 학습에 사용되지 않는 데이터가 필요
- AIDU ez에서의 데이터 비율

- 모델 학습 후의 상태
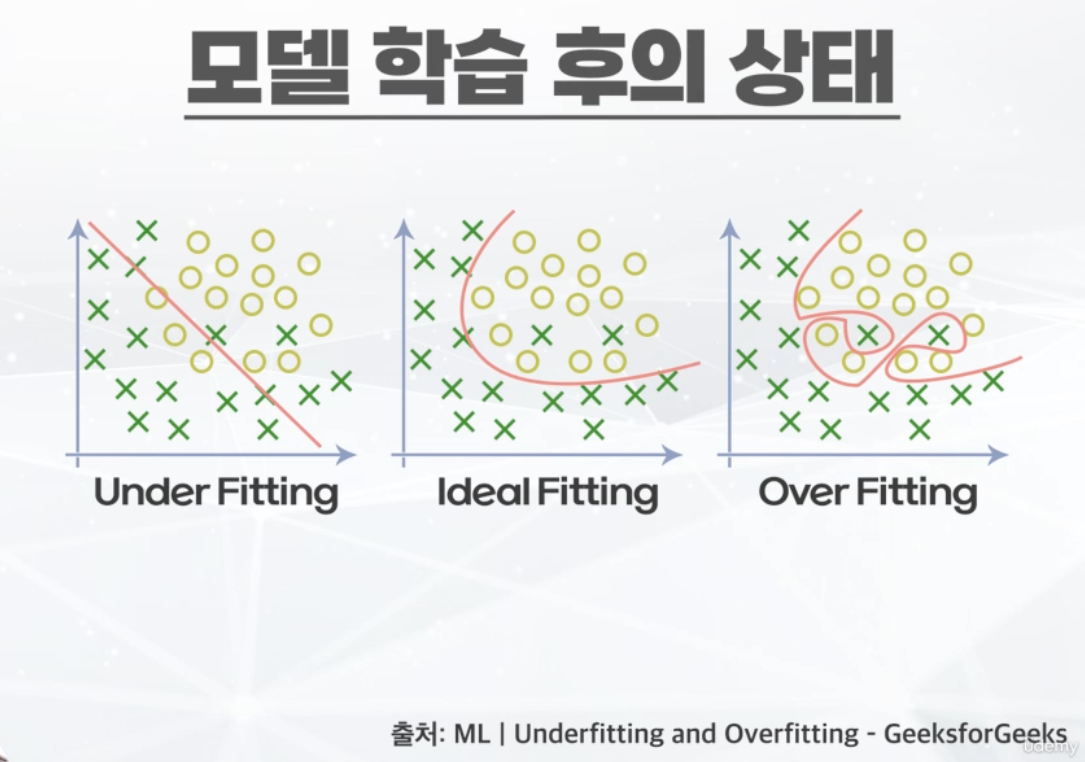
- 과소 적합(Under Fitting) : 학습을 너무 적게 진행한 상태
-- 해결 방법 : 학습 반복 횟수를 더 늘려주면 해결 가능
- 과대 적합 (Over Fitting) : 훈련 데이터로 너무 학습해 편향된 상태, 훈련 데이터에서만 성능 좋고 검증 및 평가 데이터에서는 성능 낮음
-- 해결 방법 : Early Stop / Drop Out
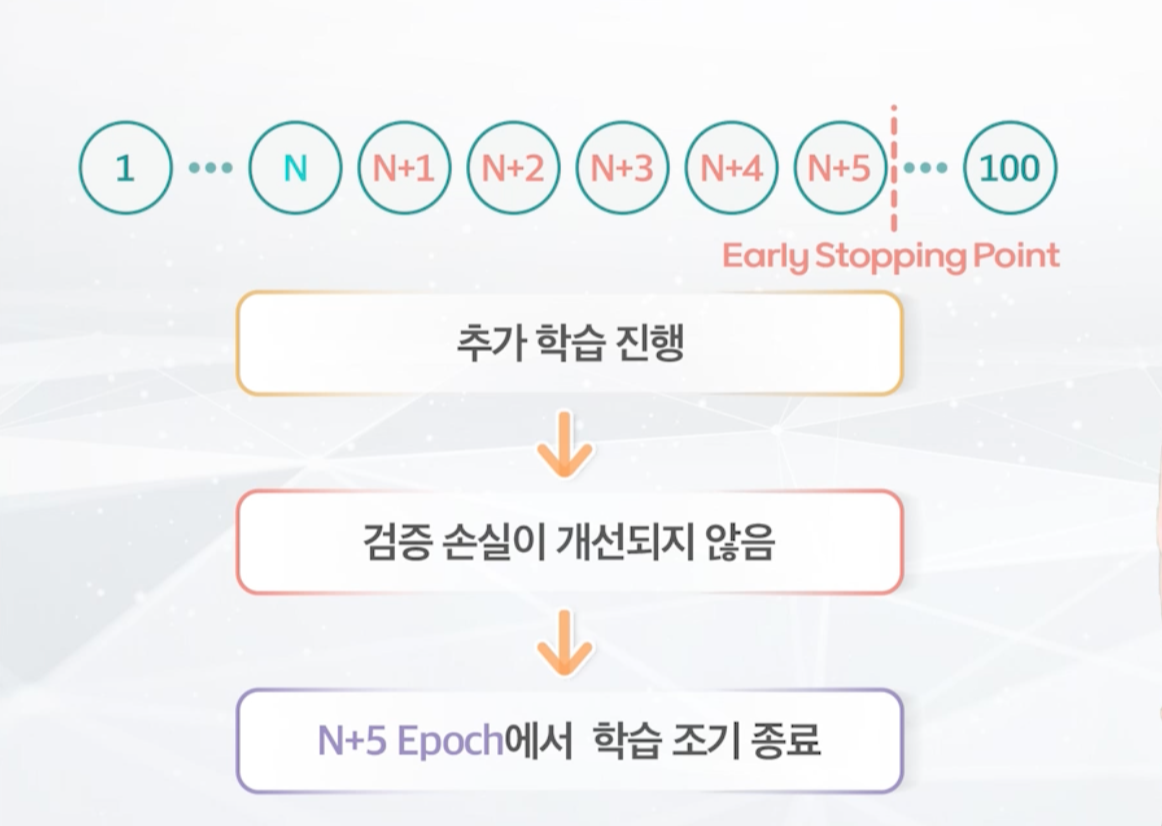
- Early Stop : 과대 적합을 막기 위해 Epoch 횟수 전 학습을 조기 종료하기 위한 파라미터
- Drop Out : 과대 적합을 줄이기 위해 임의로 노드를 제거해주는 확률 수준 (딥러닝 알고리즘)
[하이퍼 파라미터 : AIDU ez 딥러닝을 중점으로]
- Epoch : 훈련 데이터 전체를 몇 번 반복해서 학습을 할지 정하는 파라미터(과소 적합시 늘려줘야 함)
- Batch Size : 데이터를 미니 배치로 나눠 효율적인 학습(가중치 업데이트)을 하기 위한 파라미터로, 미니 배치에 들어가는 데이터 크기
-- 학습 데이터 전체로 한 번에 학습할 경우, 매우 느리고 가용한 리소스를 넘는 계산이 필요할 수 있음.
- Iteration : 데이터 크기를 배치 사이즈로 나눈 횟수(모델의 가중치 업데이트가 일어나는 횟수)
-- 단, 가중치 업데이트는 훈련 데이터로 학습할때만 이루어지므로, 훈련 데이터에 대해서만 나누어 계산한다.

- Early Stop : 과적합 방지용 기준값, 검증 데이터에 대한 Loss 값이 Early Stop의 수치만큼 반복해서 줄어들지 않으면, 학습 중지
[평가 지표]
- 종류, 과제에 맞는 평가지표를 선택해야 함
- 비교 대상을 적절히 선정해야 함
| 지도 학습 모델 평가 지표 예시 | |
| 회귀 모델 | 분류 모델 |
| MAE | Accuracy |
| MSE | Precision |
| RMSE | Recall |
| R2 Score | F1-Score |
[회귀 모델 평가 지표]
- MAE(Mean Absolute Error)
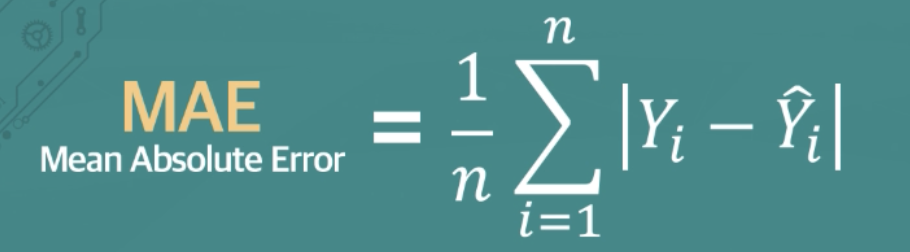
- MSE(Mean Squared Error)
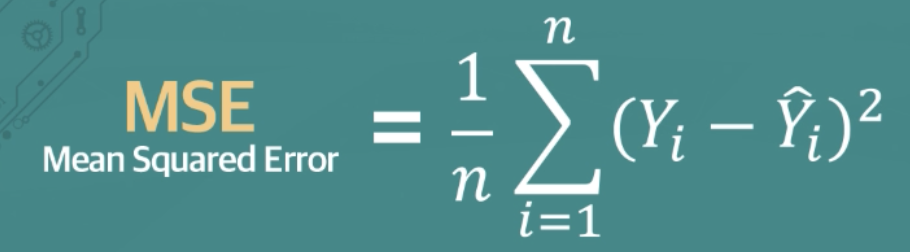
제곱을 하므로 에러가 크면 그에 대한 가중치가 더 높다
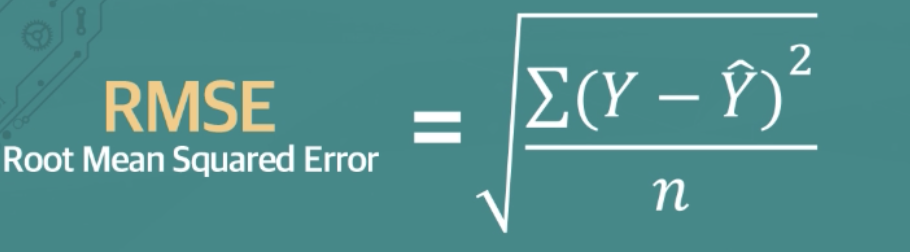
- RMSE(Root Mean Squared Error)
- R2 Score (Coefficient of Determination)
-- 회귀 모델이 얼마나 설명력 있는지를 나타내는 지표
-- 예측값과 실제값의 강한 상관 관계 여부로 요약
-- 오차를 직접적으로 표현한 위 3개와 다르게 상관 관계이므로, 값이 1에 가까울수록 모델 성능이 좋다
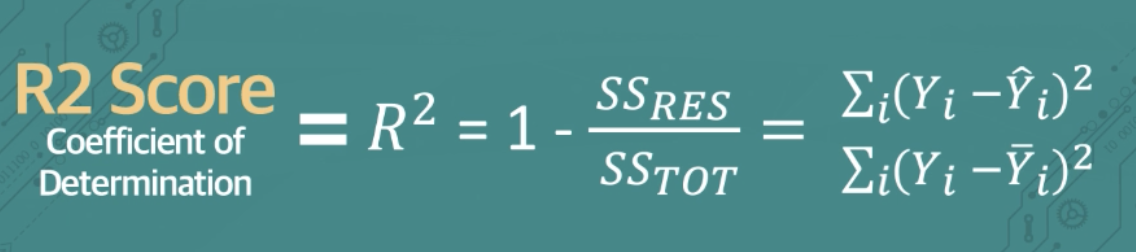
[분류 모델 평가 지표]
- 정확도(Accuracy) : 전체 데이터 중 예측에 성공한 비율

- 정밀도(Precision) : 양성이라 예측한 데이터 중 실제로 양성인 비율
-- 스팸 메일과 같이 실제 음성(중요 메일)인 데이터를 잘못 판단하면 안되는 경우에 사용(음성을 양성으로 잘못 예측하는 FN을 최소화)

- 재현율(Recall) : 실제로 양성인 데이터 중 내가 양성이라 예측한 비율
-- 암 진단과 같이 실제 양성인 데이터를 잘못 판단하면 안되는 경우에 사용(양성을 음성으로 잘못 예측하는 FN을 최소화)

- F1-Score : Trade-Off 관계의 정밀도와 재현율을 조화평균해 포괄적인 정보를 나타내는 지표

- 혼동 행렬(Confusin Matrix) : TP, TN, FP, FN으로 구성된 행렬

[평가 기준]
- 비교 대상이 없는 경우 좋고 나쁨을 구분할 수 없으므로 적절한 방식을 취해야 함
-- 유사 AI 과제의 모델 성능을 비교 대상으로 잡기
-- 베이스 라인(baseline) 모델과 비교하기
-- 기존 방식(수작업, 자동화 도구)의 성능을 지표화해서 비교 대상으로 잡기
-- 설문 조사 등으로 사용자의 만족 기준 설정
- 모델의 성능을 개선 시키는 방법
-- 더 많은 수의 학습 데이터 사용
-- AI 알고리즘 변경
-- AI 알고리즘의 하이퍼파라미터 변경
-- 피쳐엔지니어링을 통해 파생 변수 생성 (무조건 성능이 좋아지는 것이 아니며, 많은 시도가 이루어져야 함)
10. AI 적용하기
- AI 적용 : 지속적 활용을 위해 AI 모델을 시스템화 및 유지보수
미래의 새로운 데이터는 학습하지 못한 특성을 가진 데이터일 수 있음
- AI 모델을 지속 가능하게 활용하는 방법 : 데이터 지속 수집 + AI 모델 업데이트
'대외활동 > AICE대학생 서포터즈' 카테고리의 다른 글
| [AICE 자격증] AICE Basic 시험 후기 및 팁 (2) | 2024.03.16 |
|---|---|
| [AICE 자격증] AIDU ez 실습 [분류] : 중공업 선박 수주 여부 예측 (7일차) (1) | 2024.03.14 |
| [AICE 자격증] AIDU ez 실습 [분류] : 항공사 고객 만족 여부 예측 (6일차) (0) | 2024.03.14 |
| [AICE 자격증] AIDU ez 실습 [회귀] : 음원 흥행 가능성 예측 (5일차) (0) | 2024.03.12 |
| [AICE 자격증] AI 구현 프로세스_1 (3일차) (0) | 2024.03.06 |
| [AICE 자격증] 노코딩 AIDU ez 활용법 (2일차) (0) | 2024.03.06 |
| [AICE 자격증] AI의 이해 (1일차) (1) | 2024.03.04 |
| [AICE 자격증] 학습 블로그 챌린지 시작 (0) | 2024.03.04 |



