
AICE 자격증 학습 블로그 챌린지 (7일차)
AICE basic 시험 대비 마지막 실습이다! 다음 포스팅은 당당히 합격 결과를 걸 수 있도록 마지막까지 힘내보겠다.
하던 것처럼 AIDU ez 플랫폼에서 주어진 연습문제를 바탕으로 직접 실습을 진행한다.
aice basic 올인원패키지 프로젝트에 내장된 연습용 실습 자료를 바탕으로 진행하지만, 공공데이터나 특정 분야의 데이터를 직접 넣어서 비슷하게 진행해 보는 것도 재미있을 것 같다.


마지막 실습이다! 역시나 학습한 AI 적용 프로세스를 기반으로 정리할 예정이다.
- AI 적용 프로세스 : 문제 정의 -> 데이터 수집 -> 데이터 분석 및 전처리 -> AI 모델링 -> AI 적용

1. 문제 정의
- 목적 : 중공업 선박의 수주시 유용한 지표가 무엇인지 파악해, 수주경쟁전략 및 마케팅을 통한 시장 우위 선점
- 목표 : AI 모델을 활용해 선박의 수주 여부를 예측 (가능 / 불가능)
2. 데이터 수집
- 실습에서 사용된 데이터
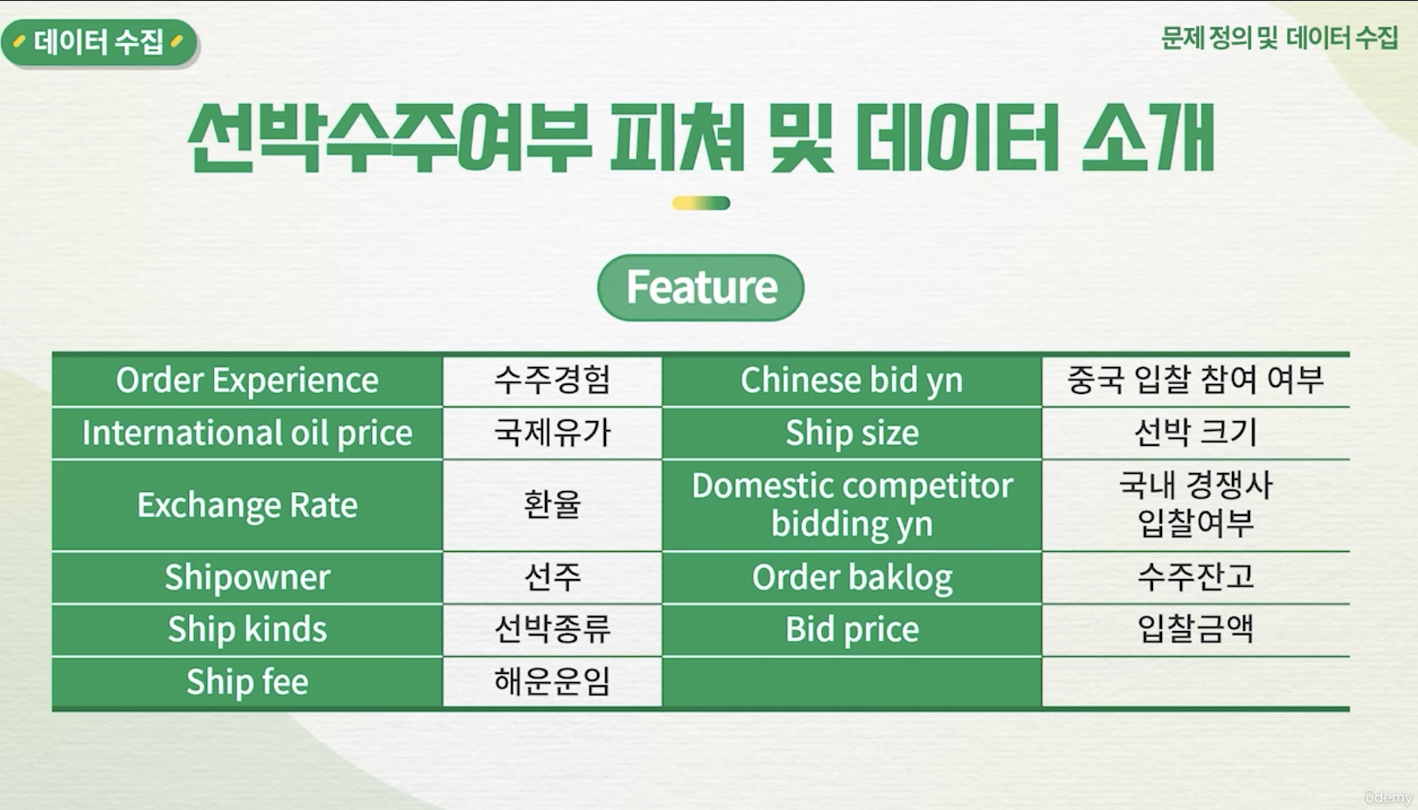
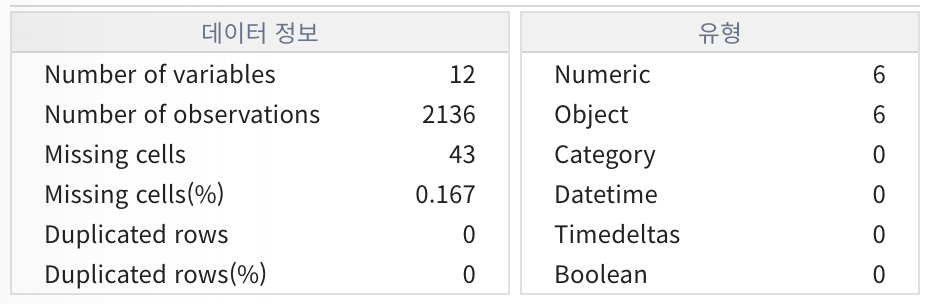
- AIDU ez를 활용한 데이터 확인 (기초 정보 분석)
- 데이터 가져오기 : final_df_eng_2_1
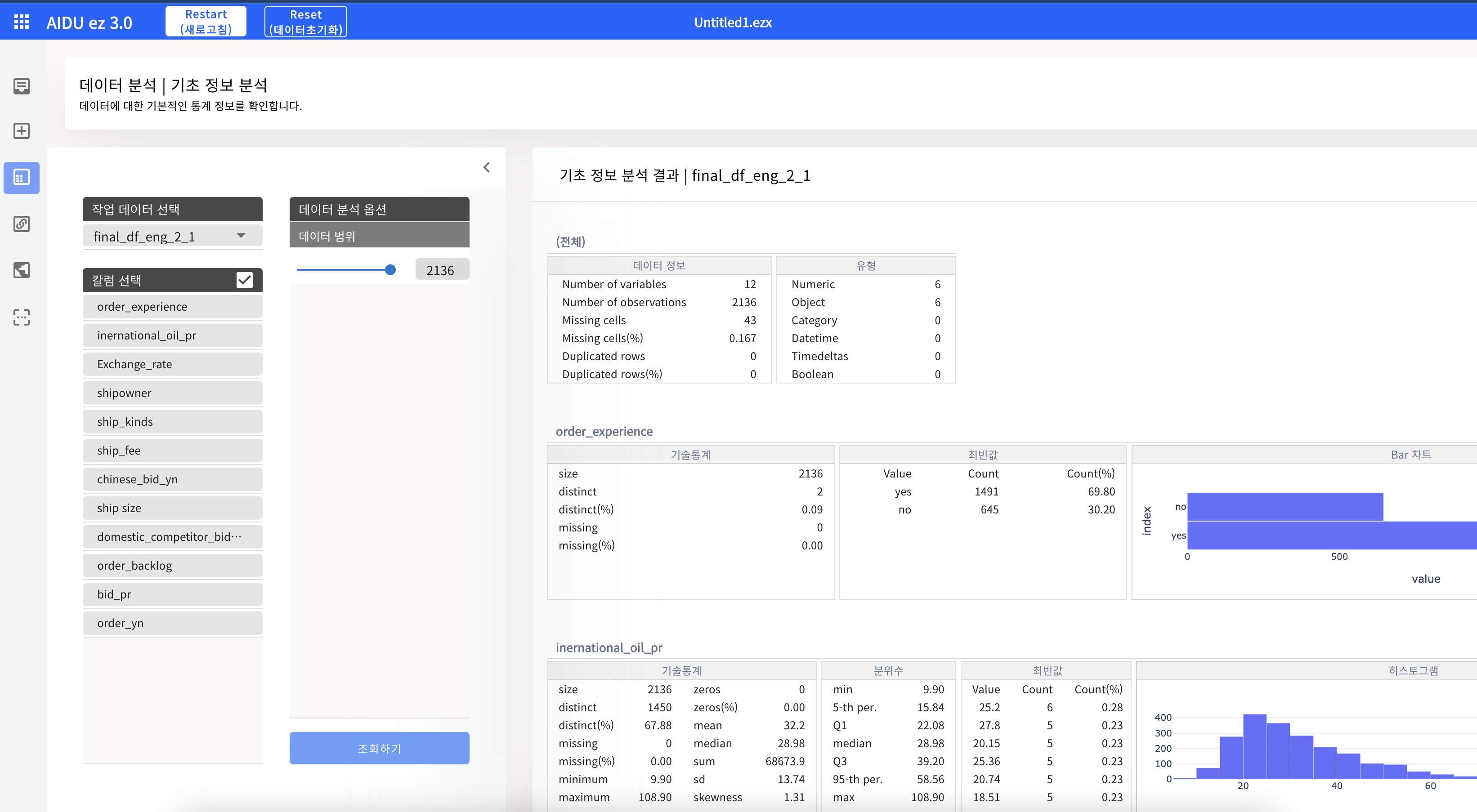
- 데이터 분석 - 기초정보분석
3. 데이터 분석 및 전처리
- 데이터 시각화를 통한 EDA(Explorative Data Analysis; 탐색적 데이터 분석)
- Feature 간 상관관계 분석 : Heat map
- Feature 자체 분석 : Box plot
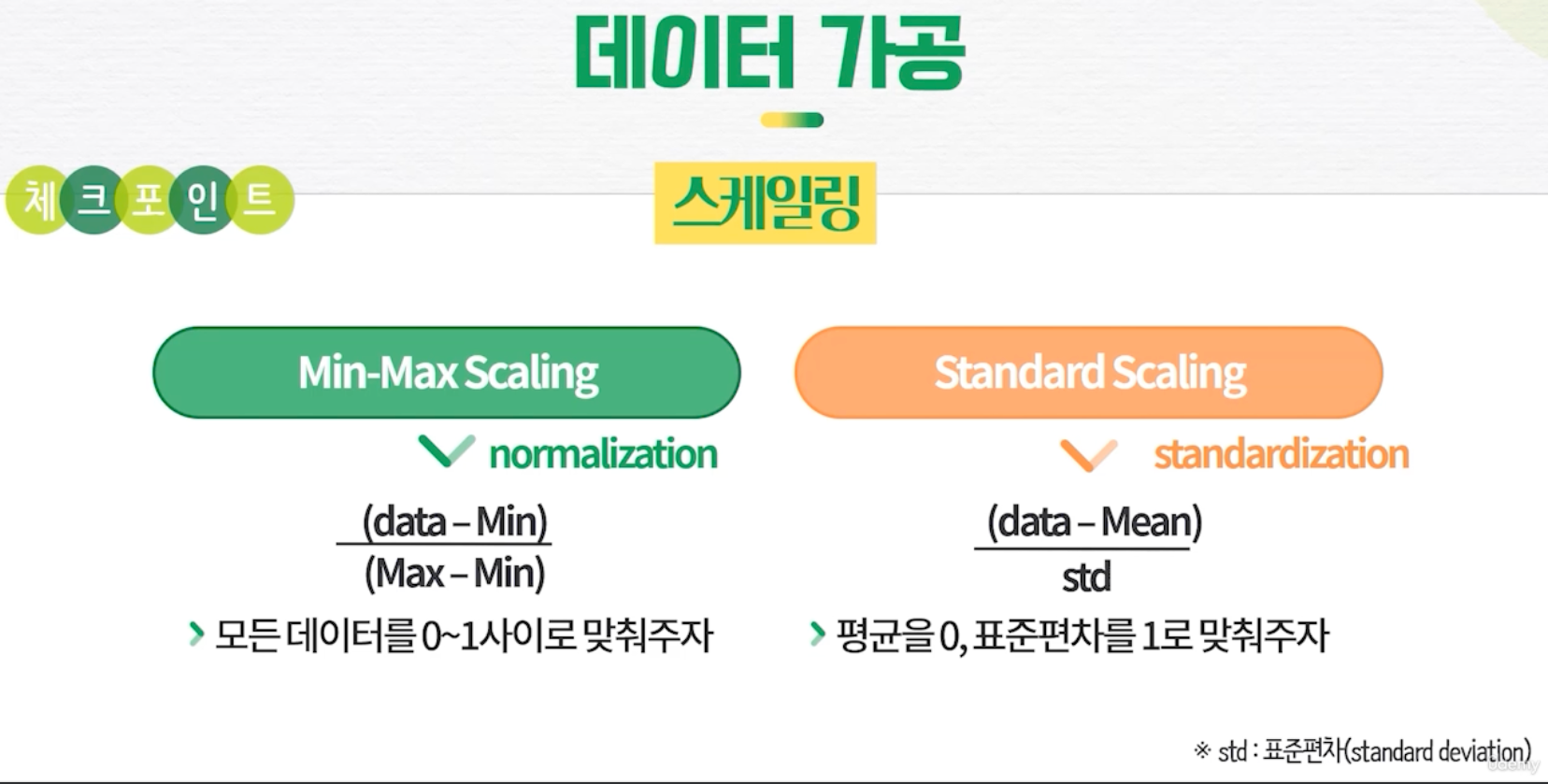
- 데이터 가공
- 스케일링 : 수치형 데이터의 범위를 비슷하게 조정해 AI 모델이 적절히 학습할 수 있도록 함
- AIDU ez 제공 스케일러 : Min-Max Scaling, Standard Scaling
- 이상치 확인 및 제거 : 이상치 제거(이상치가 적을 경우) 또는 대체, 분류 모델의 경우 상황에 따라 이상치를 그대로 두기도 함
- 인코딩 : 순서 여부에 따라 범주형 모델을 적질히 수치화(One-Hot Encoding, Original Encoding)
- 결측치 처리 : 결측치가 포함된 행, 열 제거 또는 대표값으로 대체
- 스케일링 : 수치형 데이터의 범위를 비슷하게 조정해 AI 모델이 적절히 학습할 수 있도록 함
AIDU ez를 활용한 데이터 분석 (통계 분석)
- 타겟 변수의 종류 확인 : 데이터 전처리의 방향성 및 AI 모델 결정
- yes와 no 2개의 Class로 구성 : 이진 분류 모델
- 두 Class가 적당한 비율로 구성된 Data : 데이터 불균형 문제 고려하지 않음(불균형시, 언더/오버 샘플링 기법 사용)

- 결측치 처리
- 결측치가 포함된 행 또는 Feature 삭제 (학습 데이터가 부족한 경우 대체를 권장)
- 결측치를 대푯값으로 대체 : 수치형(평균/중앙값 : 극단적인 이상치가 있는 경우 중앙값 권장), 범주형(최빈값)

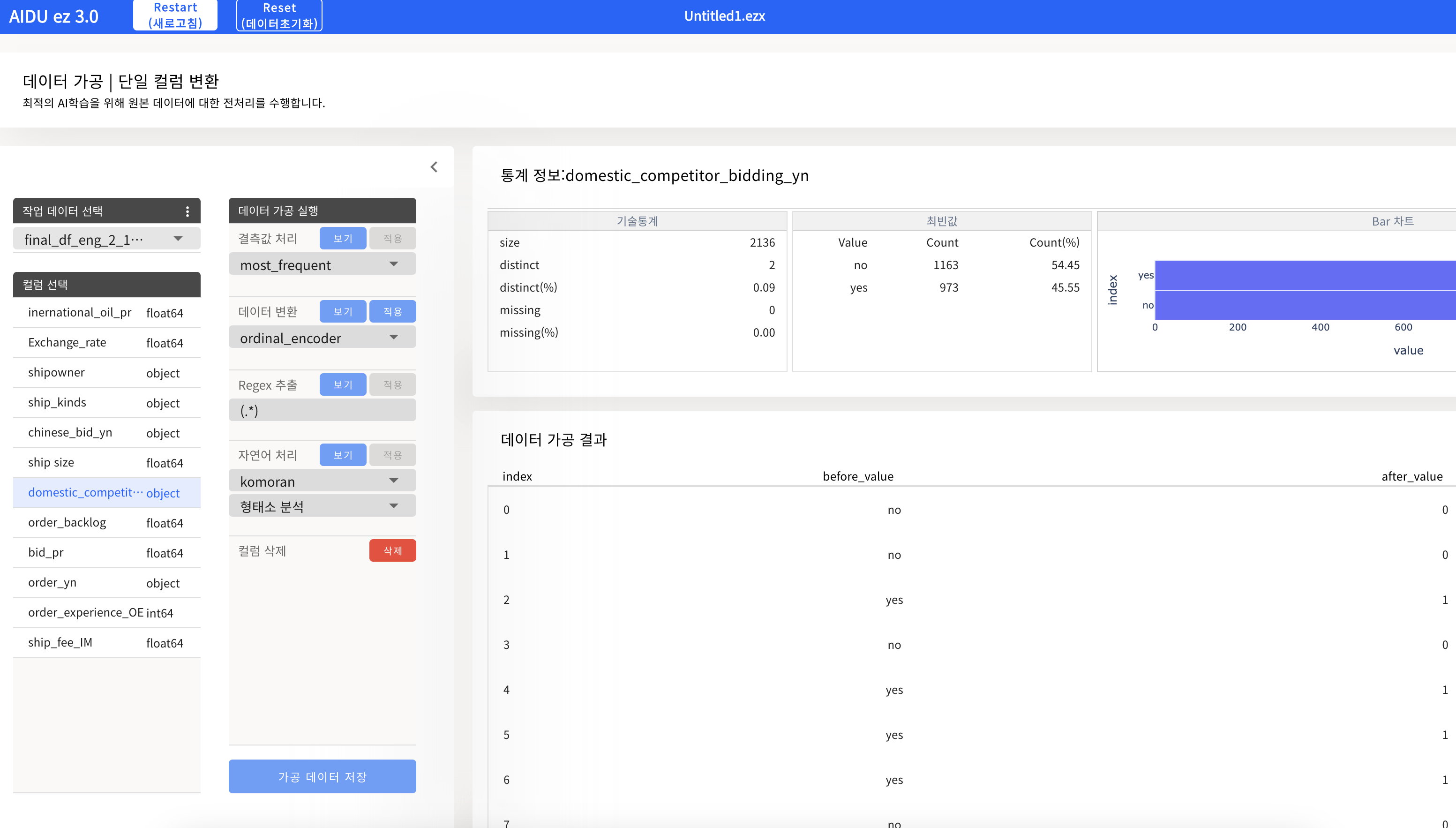
- 인코딩
- One-Hot Encoding : 순서가 무의미한 범주형 Feature에 적용
- Original Encoding : 순서가 유의미한 범주형 Feature에 적용
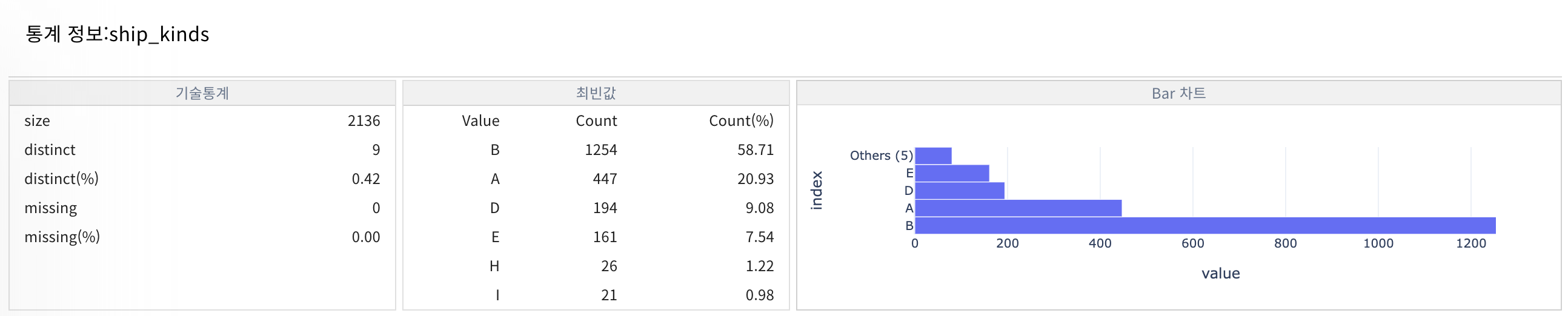
(ship_kinds는 5개로 분류되며 순서가 무의미하므로 원-핫 인코딩을 해야한다)
AIDU ez를 활용한 데이터 분석 (시각화)
- 데이터 분석 - 시각화 - 히트맵
- (!) 타겟 변수가 Object형이므로 히트맵을 통해 Feature들과의 상관관계를 보기 위해서는 먼저 인코딩으로 수치화해야함.
- 히트맵을 통한 feature 간 상관관계 분석하기 (인과관계가 아닌 상관관계임에 주의)
- 마우스를 통해 상관관계 값을 수치적으로 확인 가능
- 마지막 행의 인코딩된 타겟 변수인 order_experience_OE와 상관 관계가 높은 feature : international_oil_pr
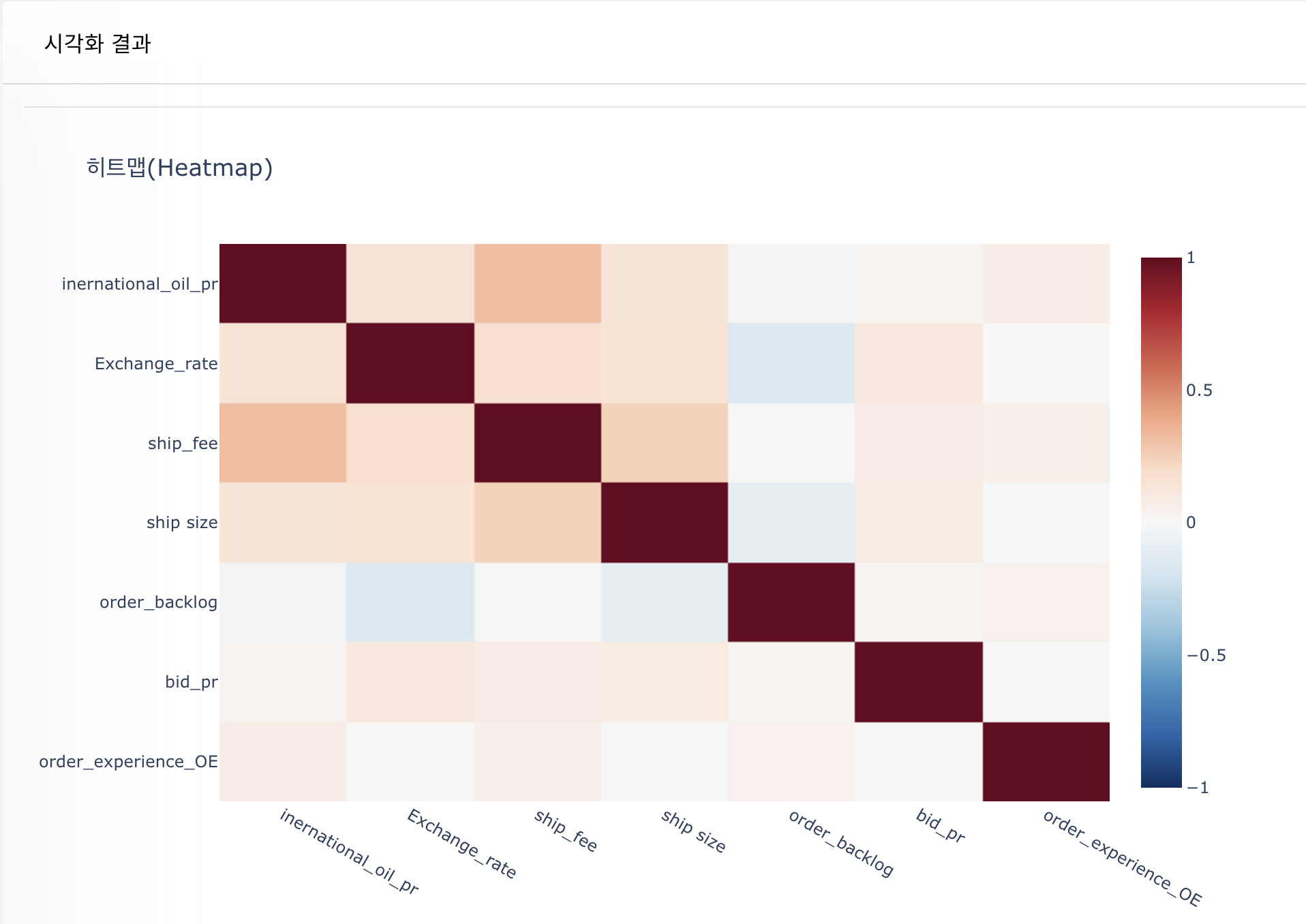
(Object형은 히트맵에 보이지 않으므로, 타겟 변수만 먼저 인코딩을 진행했다. 만약 성별 등의 다른 object형과의 히트맵이 궁금한 경우, 먼저 object형에 대해서 적절히 인코딩을 한 후 가공 데이터를 저장해 히트맵을 보면 된다)
- 데이터 분석 - 시각화 - 박스차트
- 박스차트를 통한 feature 자체 분석하기 (데이터 분포, 이상치 등을 시각적으로 확인)
- 이상치 : Q3 + IQR * 1.5 이상 또는 Q1 - IQR * 1.5 이하 데이터 (IQR = Q3 - Q1)
- 이상치가 많은 경우, Standard Scaling 사용 권장
- 마우스를 통해 박스차트 구성 값을 수치적으로 확인 가능
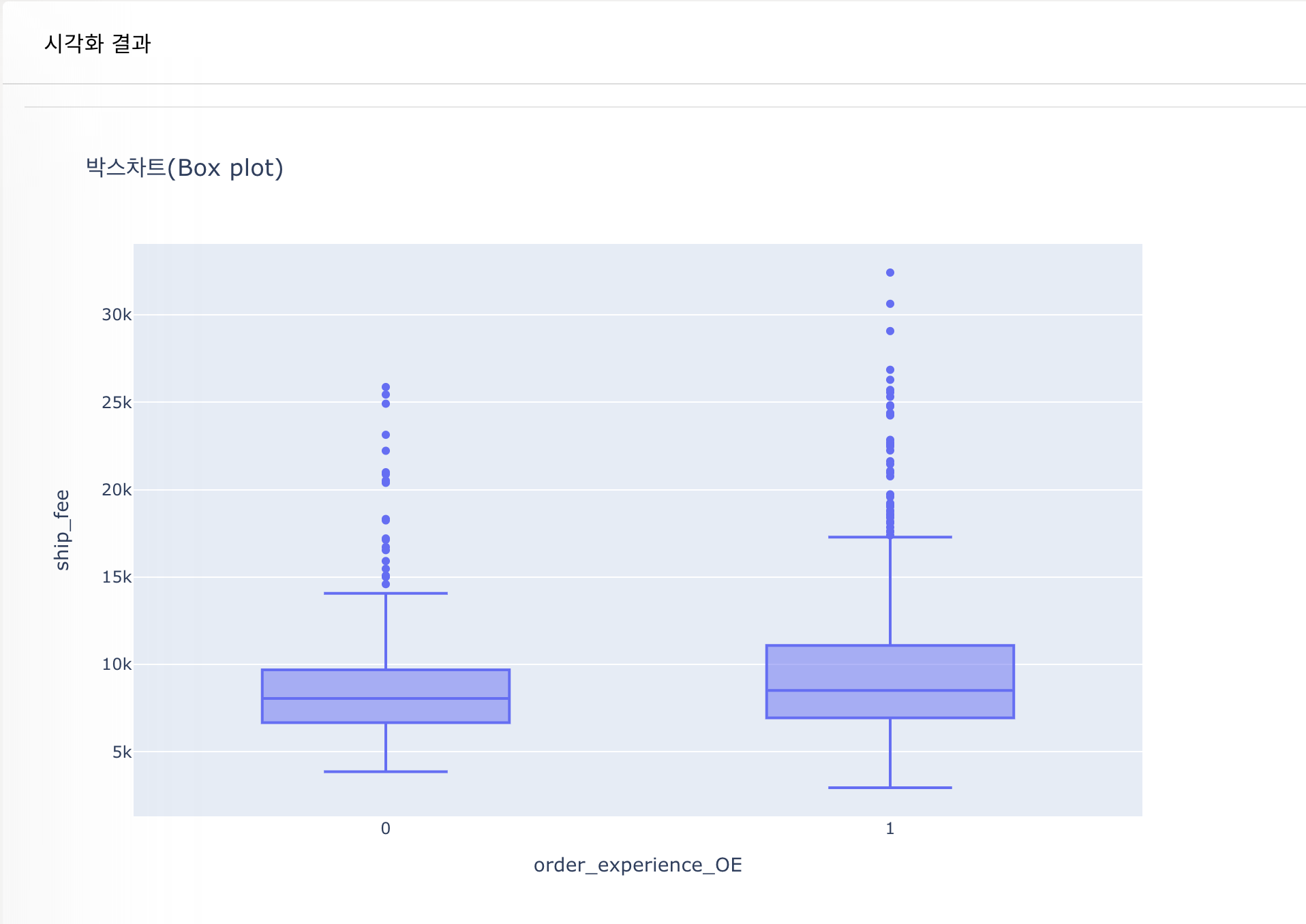
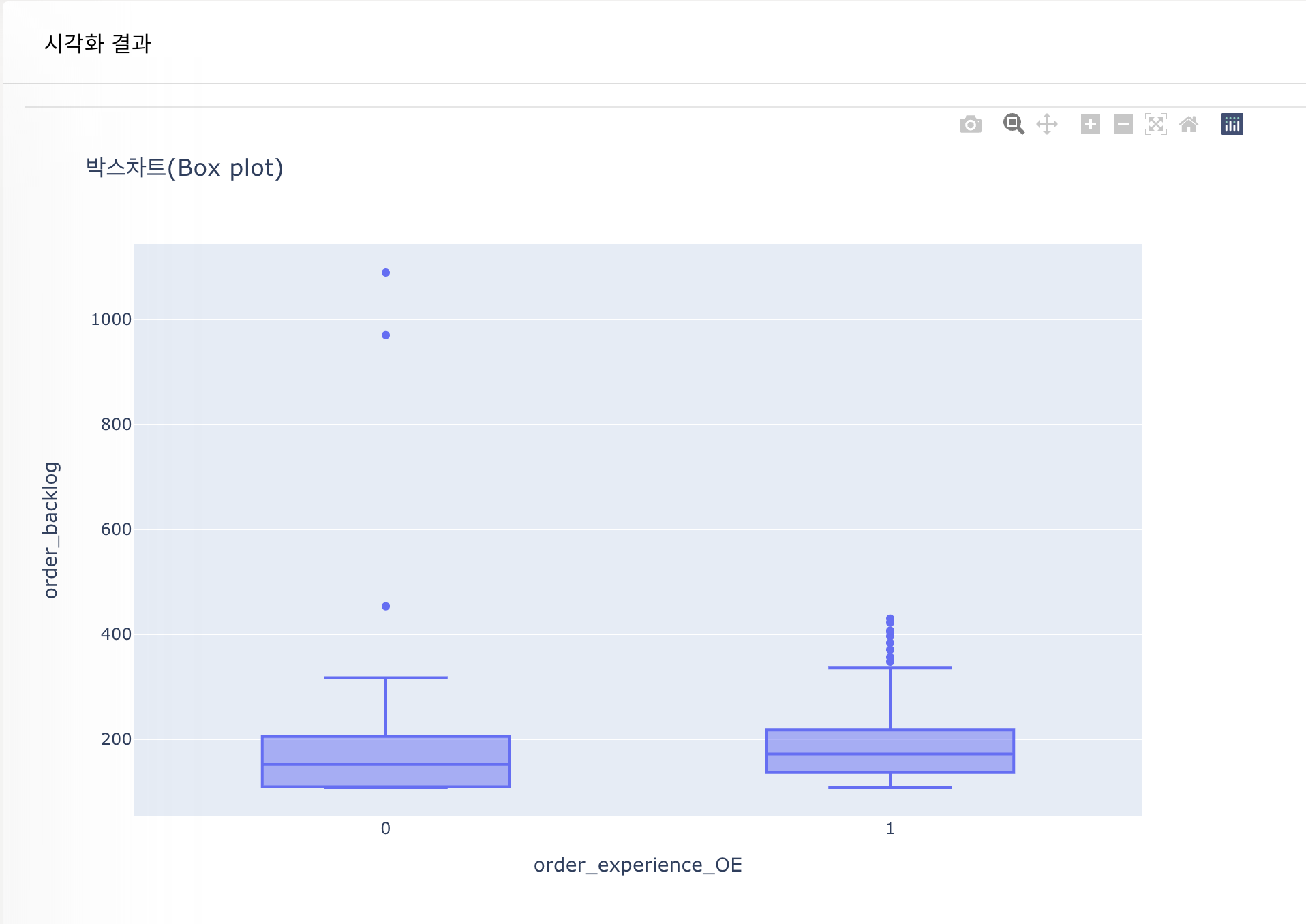
이번 실습에서는 모든 컬럼에 대해 이상치가 존재했다. 기본적으로 Standard Scaling을 하며, 일부 이상치는 적절히 수정한다면 모델의 성능이 더 높아질 것으로 예상된다.
AIDU ez를 활용한 데이터 전처리
- 데이터 분석을 통해 얻은 인사이트를 바탕으로 데이터 전처리를 진행 : 보기 -> 적용
- 상관관계가 낮은 Feature 컬럼 삭제 : 차원의 저주를 해결하기 위함
- 결측치 처리 (반드시 인코딩 및 스케일링 전에 처리할 것)
- 인코딩 / 스케일링
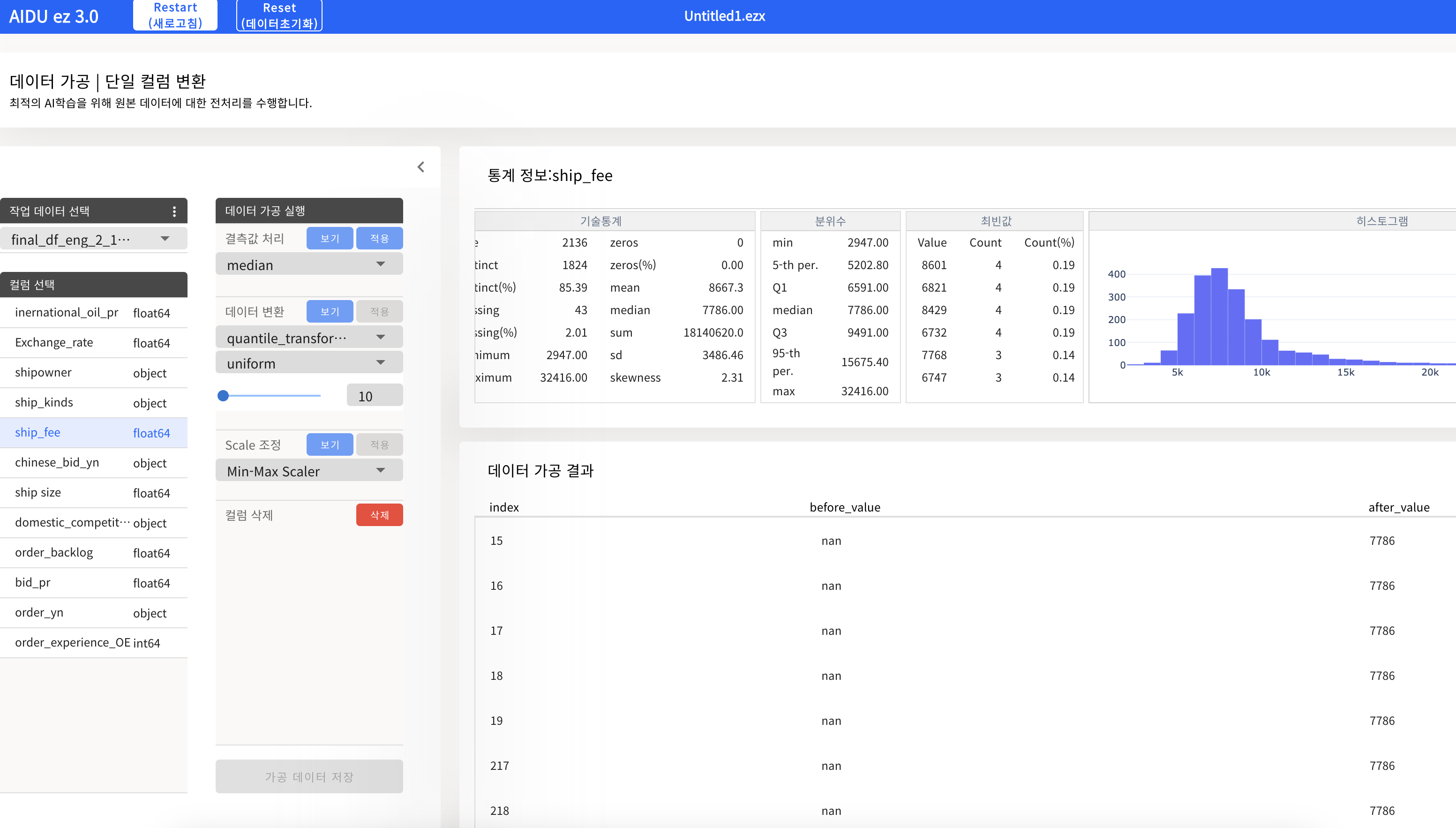
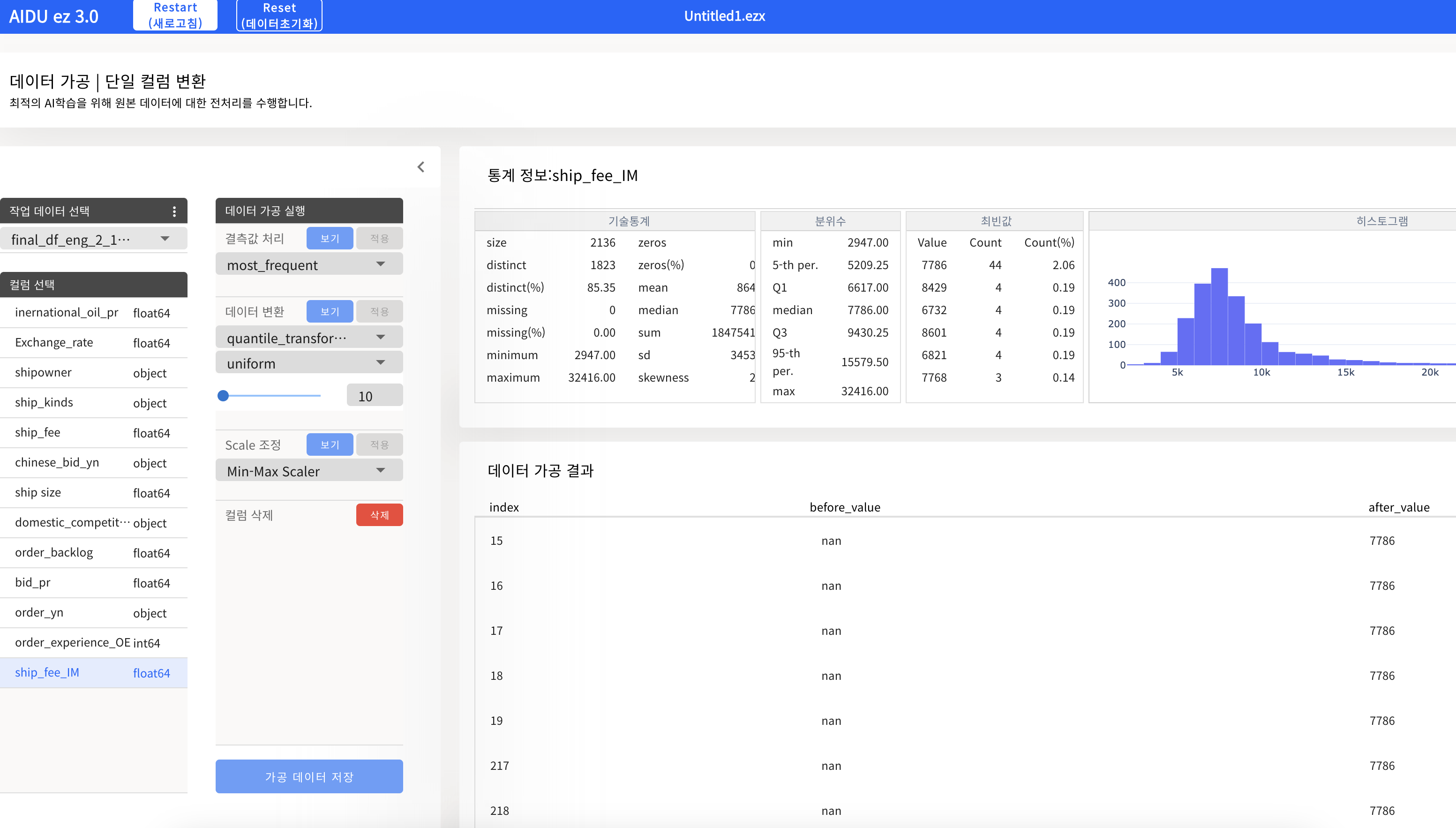
(AIDU ez에서 데이터 가공을 할 경우, 원본 Feature을 변경하는 것이 아니라, 원본을 가공한 새로운 Feature을 추가하므로, 데이터를 가공한 후 원본 컬럼을 삭제하면 된다. + 이후 모델학습할때 원본 컬럼을 제외시킬 수 있으므로 취향껏 삭제 또는 제외하자)
(ship_kinds류의 경우, 원-핫 인코딩을 하려 했으나, 존재하지 않는다. Object형 자체가 분류형인 듯하니 따로 건들지 않았다.)
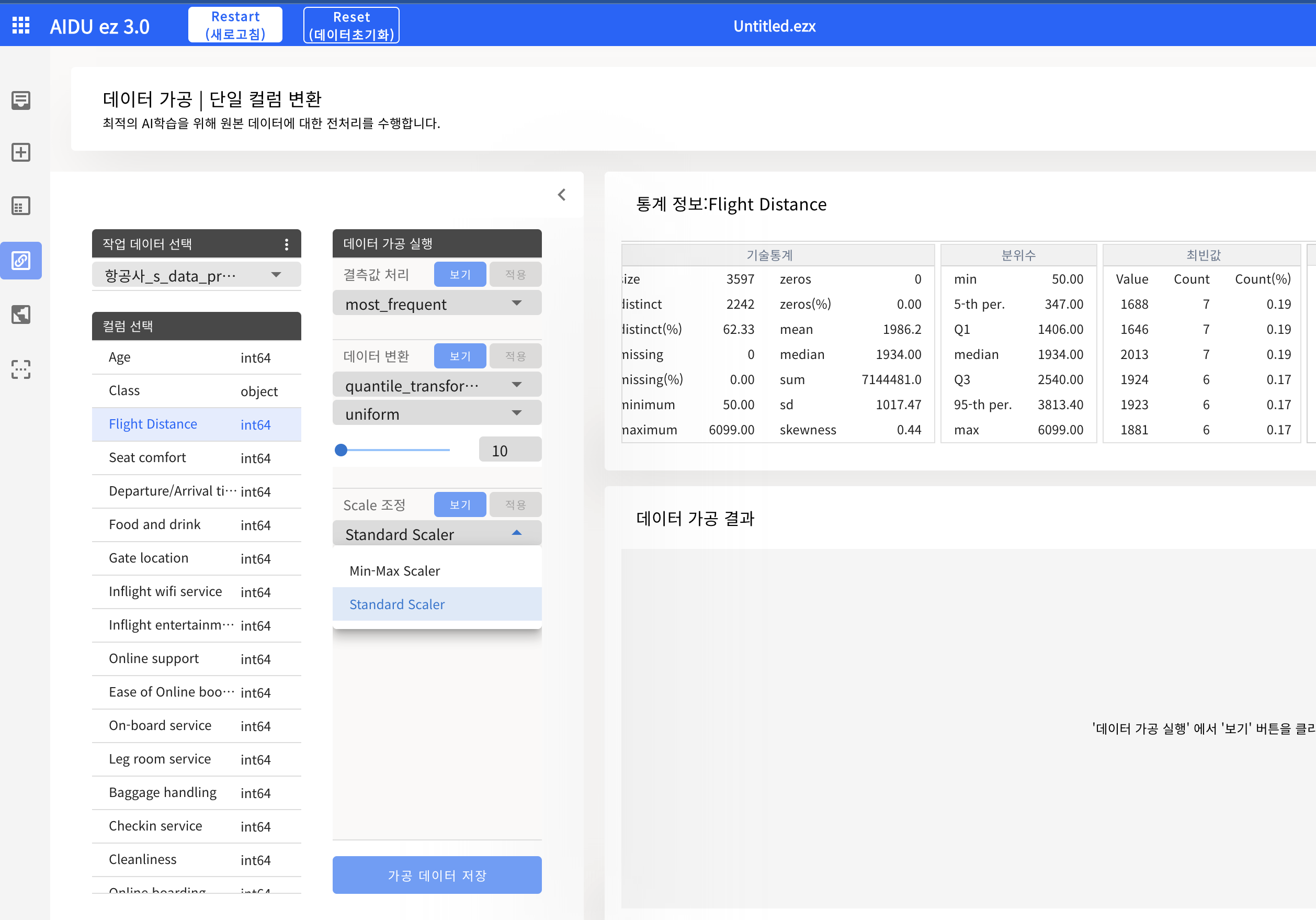
(이번 실습은 대부분의 컬럼이 모두 이상치가 어느정도 존재하므로 모두 Standard 스케일링을 적용했다)
- 모든 데이터에 대해 적절히 전처리를 한 경우 하단의 가공 데이터 저장을 통해 진행사항을 저장하고 AI 모델링으로 넘어갈 수 있다.
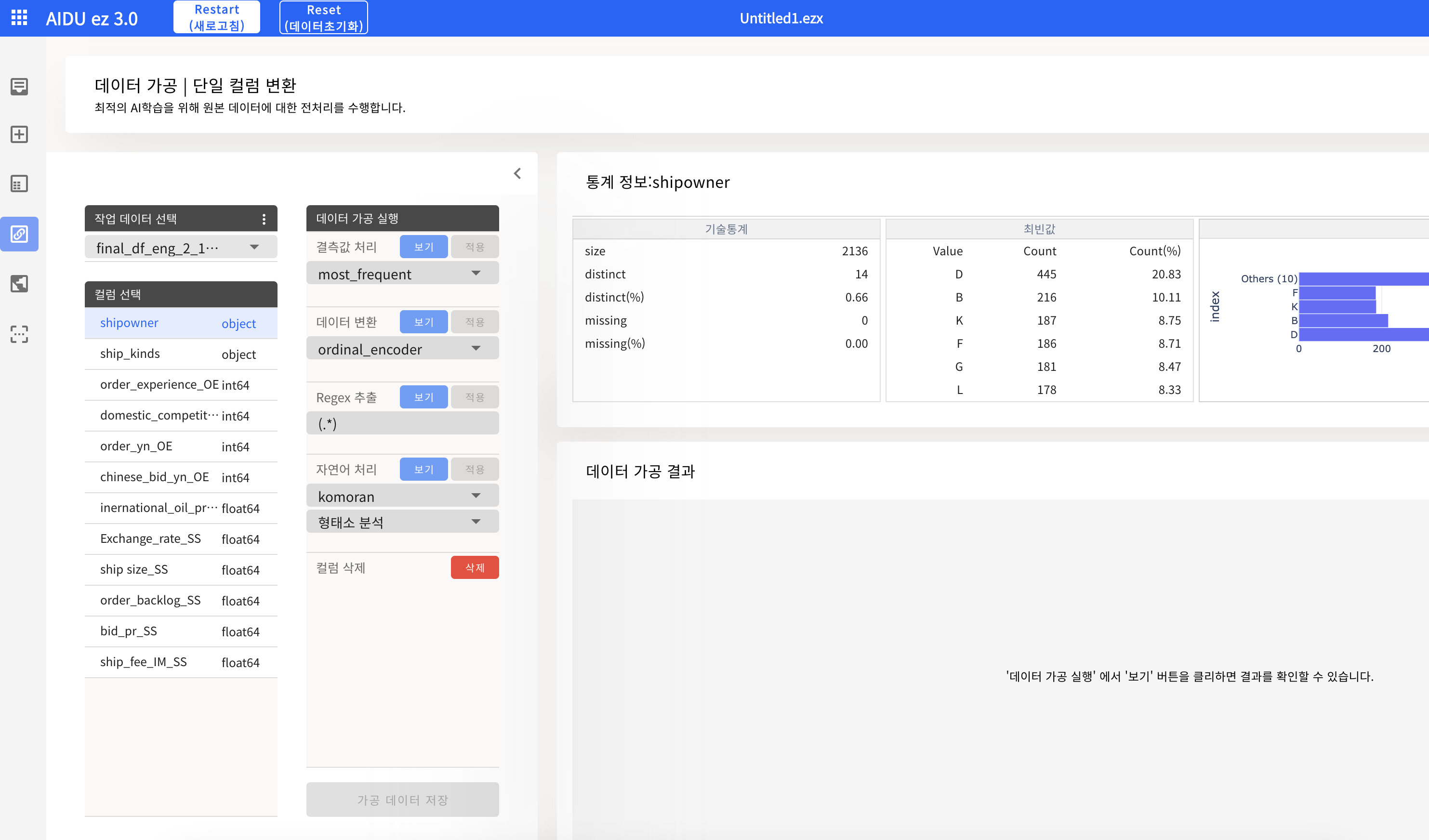
4. AI 모델링
- AI 분류 모델 성능평가 지표
- 정확도(Accuracy) : 전체 데이터 중 예측에 성공한 비율
- 정밀도(Precision) : 양성이라 예측한 데이터 중 실제로 양성인 비율
- 재현율(Recall) : 실제로 양성인 데이터 중 내가 양성이라 예측한 비율
- F1-Score : Trade-Off 관계의 정밀도와 재현율을 조화평균해 포괄적인 정보를 나타내는 지표




- AI 모델 학습 : 딥러닝 학습
- 전처리 완료한 작업 데이터 선택
- 타겟 변수인 order_yn_OE를 Output 컬럼으로 이동 (화살표 버튼 클릭)
- Input 컬럼 중 범주형 데이터는 데이터 유형을 category로 변경
- 모델 유형을 classifier으로 변경
- 모델 및 파라미터 설정
- 학습을 완료한 후에는 모델을 저장 (캡처본에는 짤려있지만 드래그를 통해 오른쪽 상단으로 가면 모델 저장 버튼이 있음)
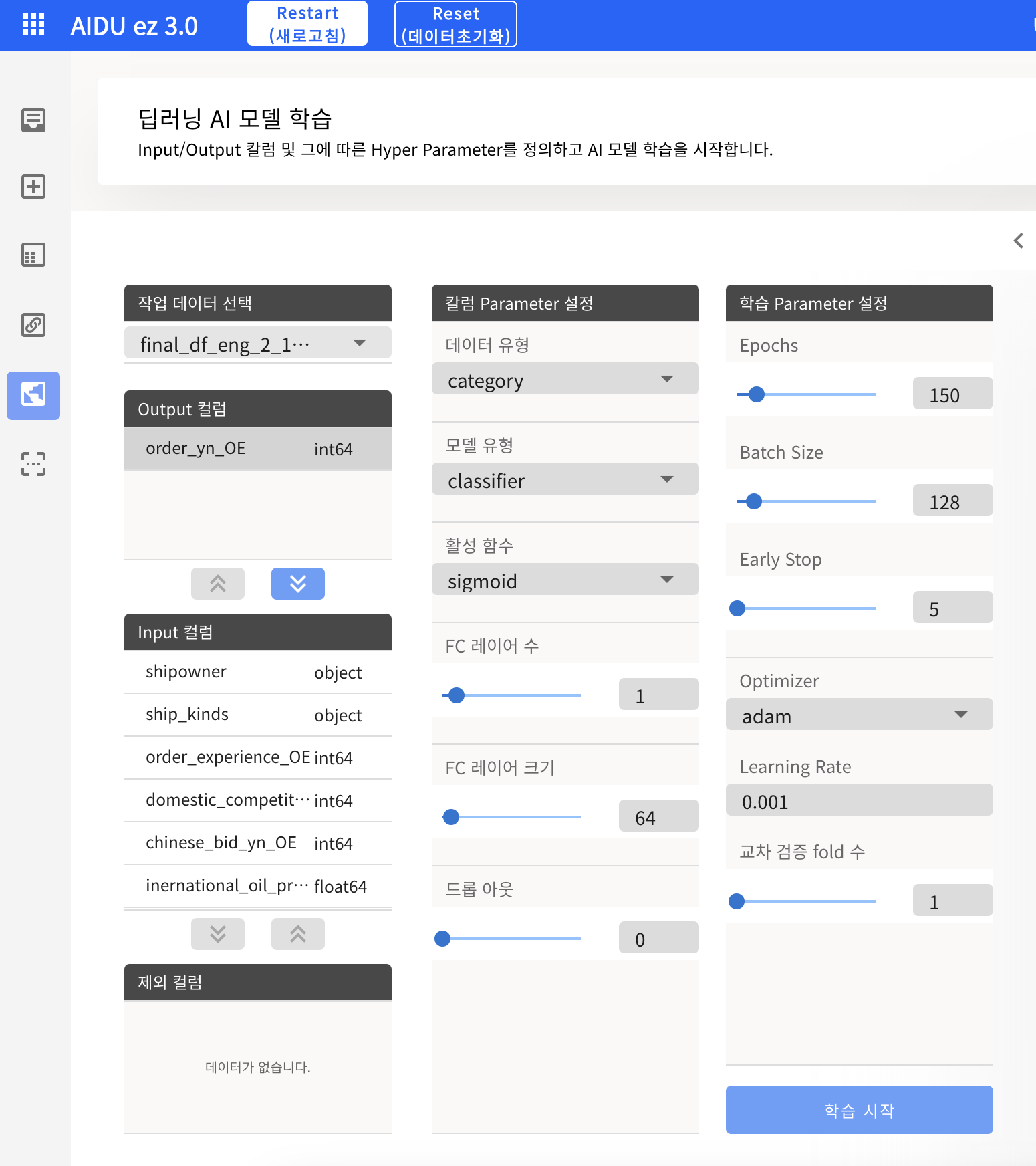
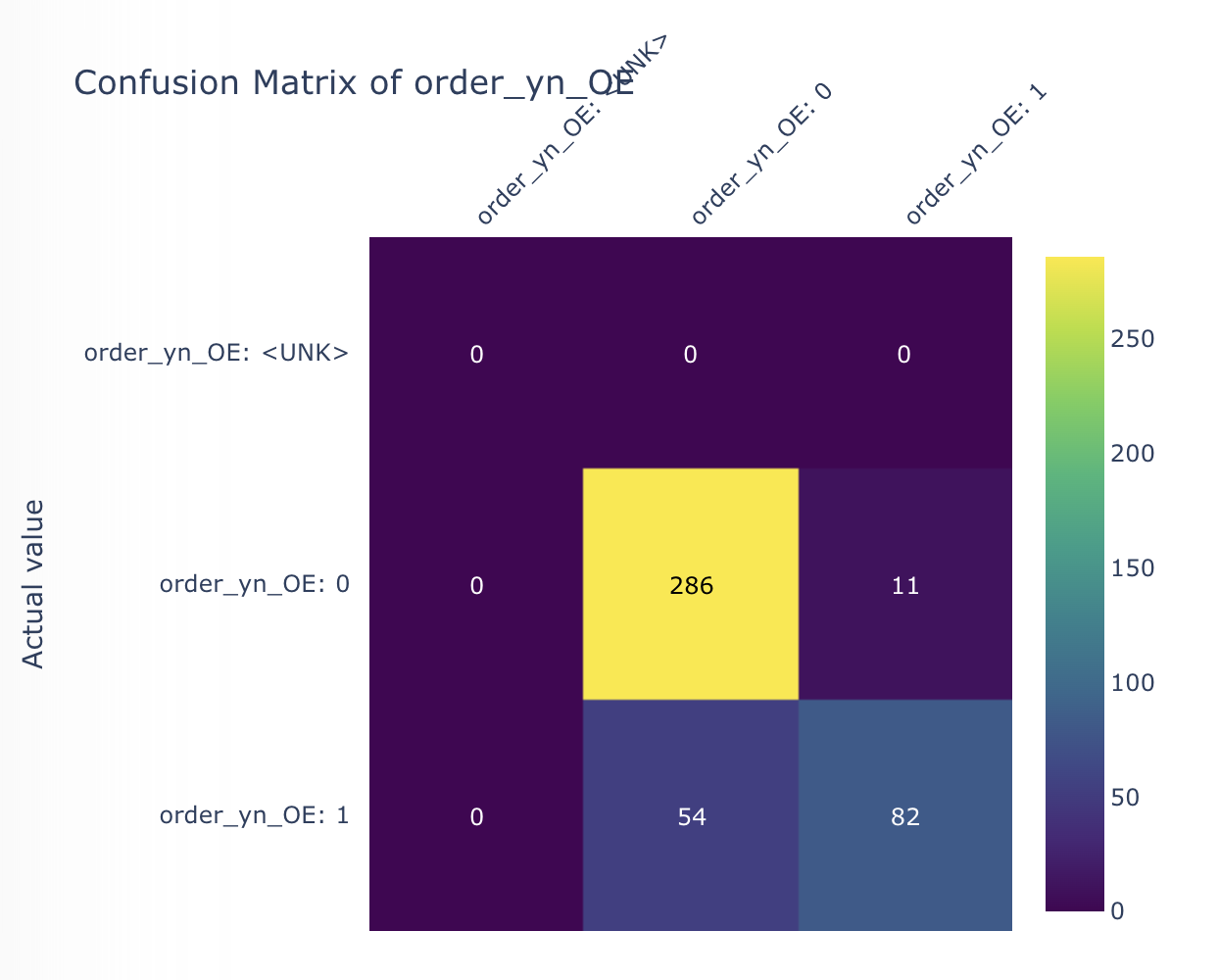
- AI 모델 성능 평가 및 피드백
- 딥러닝 모델의 성능 지표를 보며 추가학습 및 파라미터 조절을 결정
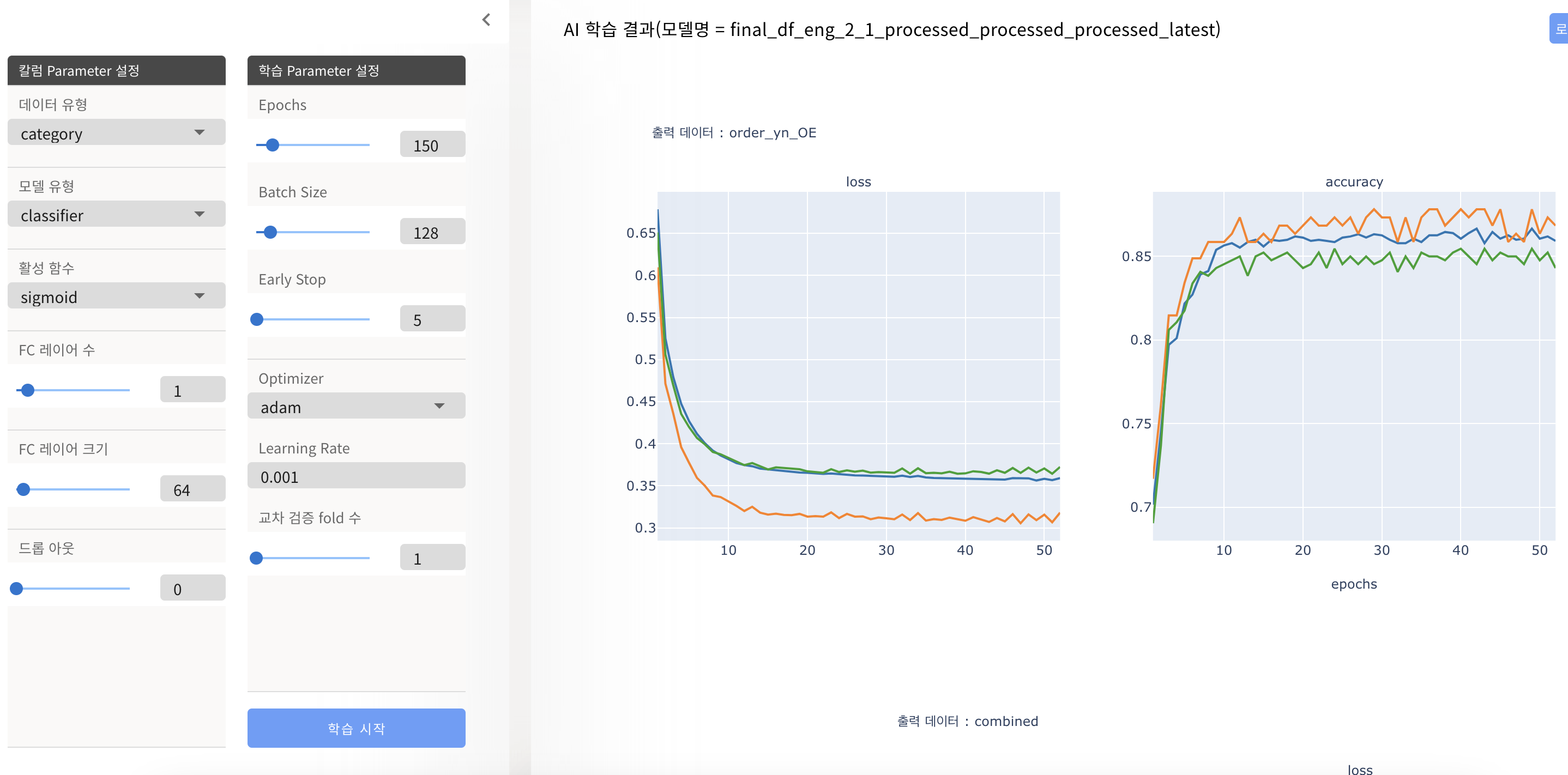
(지표에서 확인해야 할 부분은 train 데이터가 아닌 validation과 test 데이터에 대한 loss, accuracy 값dlek. epoch 10 부근에서 validation[주황색]과 test[초록색]의 성능이 거의 오르지 않는 것을 확인함. 또한 early stop 옵션에 따라 50 초반에서 멈춘 것을 확인함.)
- AI 모델의 성능을 높이는 방법
- 더 많은 수의 학습 데이터를 사용
- AI 모델 알고리즘 변경
- 피처엔지니어링을 통한 파생 변수 생성
- AI 모델 알고리즘의 하이퍼파라미터 변경
5. AI 적용
- AIDU ez는 저장한 AI 모델을 바탕으로 다음 기능을 제공한다.
- 분석하기
- 변수 영향도 확인
- 시뮬레이션
- 예측하기
- 다운로드
- 삭제하기분석하기 버튼을 통해 해당 AI 모델의 각종 성능 지표를 확인할 수 있다.
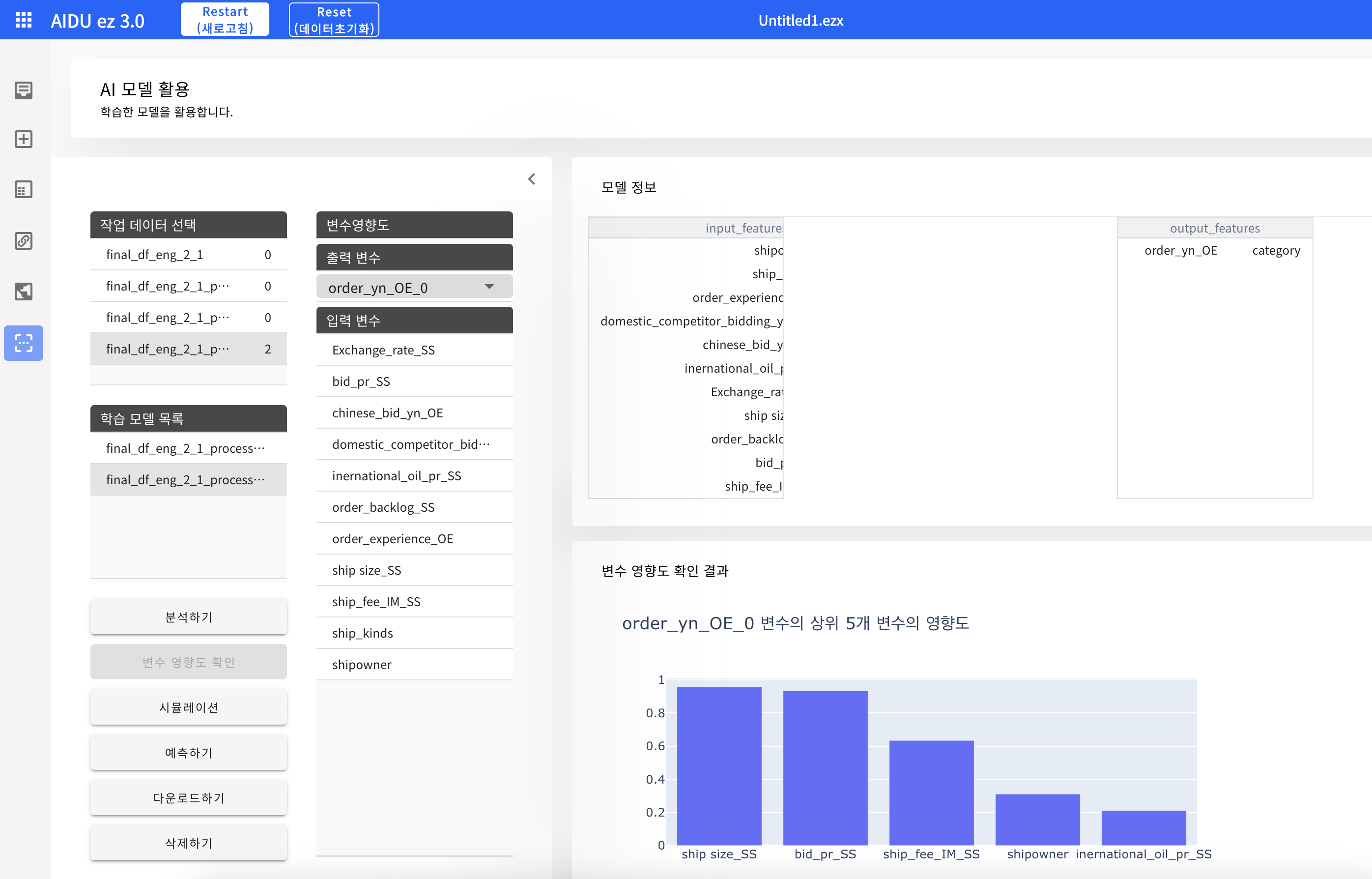
- 최종적으로 완성한 AI 딥러닝 모델은 다음 5개의 Feature에 크게 영향을 받았음을 확인할 수 있다.
주의사항 : AICE basic 시험 시 모델을 평가하는 데이터가 우리가 전처리한 것처럼 처리되지 않은 데이터로 평가하는 경우, 평가를 제대로 할 수 없거나 낮은 점수를 받을 수 있다. 따라서 시험에서 모델을 평가하는 데이터 기준에 맞춰 전처리를 진행해야 한다. 특히 타겟 라벨의 경우 우리는 0과 1로 바꿔서 모델링했는데, 시험 평가 시 "yes"와 "no"(원본)로 평가하는 경우 제대로 된 평가를 받을 수 없다.
그러므로 평가 데이터에 대한 별다른 사항이 없다면 전처리는 어디까지나 데이터를 분석하는 것에만 사용하며 원본을 변경하는 것은 결측치 채우기만을 하는 것이 좋을 수 있다.
'대외활동 > AICE대학생 서포터즈' 카테고리의 다른 글
| [AICE 자격증] AICE Basic 시험 성적 & 오픈배지 (0) | 2024.04.08 |
|---|---|
| [AICE 자격증] AICE Basic 시험 후기 및 팁 (2) | 2024.03.16 |
| [AICE 자격증] AIDU ez 실습 [분류] : 항공사 고객 만족 여부 예측 (6일차) (0) | 2024.03.14 |
| [AICE 자격증] AIDU ez 실습 [회귀] : 음원 흥행 가능성 예측 (5일차) (0) | 2024.03.12 |
| [AICE 자격증] AI 구현 프로세스_2 (4일차) (0) | 2024.03.07 |
| [AICE 자격증] AI 구현 프로세스_1 (3일차) (0) | 2024.03.06 |
| [AICE 자격증] 노코딩 AIDU ez 활용법 (2일차) (0) | 2024.03.06 |
| [AICE 자격증] AI의 이해 (1일차) (1) | 2024.03.04 |



