
AICE 자격증 학습 블로그 챌린지 (5일차)
변명 아닌(?) 변명을 하자면 교환학생에 필요한 서류를 얻기 위해 교수님이랑 면담도 하고 뭔가 작성도 많이 해서 금토일은 잠시 멈췄다...
이번 주 금요일에 AICE 자격증 시험을 보니 남은 시간동안 열심히 학습하고 내용을 정리하겠다...!
오늘부터는 배운 이론들을 바탕으로 AIDU ez 플랫폼에서 직접 실습을 진행한다.
진행하는 실습 자료는 AICE 시험대비로 주어진 Basic 올인원패키지 프로젝트에 내장되어 있어 편하게 연습할 수 있었다.
이 실습을 포함해 총 3가지 실습이 있는데, 학습 내용을 일관되게 적기 위해, 학습한 AI 적용 프로세스를 기반으로 정리할 예정이다.
- AI 적용 프로세스 : 문제 정의 -> 데이터 수집 -> 데이터 분석 및 전처리 -> AI 모델링 -> AI 적용
사실 유데미에서 제공한 실습 강의도 이렇게 제공한다
1. 문제 정의
- 목적 : 음원 투자 리스크를 최소화해 투자 효율을 극대화
- 목표 : AI 모델을 활용해 흥행이 가능한 음원을 예측
2. 데이터 수집
- 예상되는 필요 데이터 정보
| 음원 메타 데이터 | 음원 자체 데이터 | 소셜 데이터 |
| 음원 사이트 및 음원 차트를 통해 입수 가능한 데이터 | 악보 및 가사 정보를 이용해 자체 생성한 데이터 | 곡명, 가수명 등을 키워드로 입수 가능한 데이터 |
| 순위 정보, 가수명, 장르, 주제, 조회수 등 | 리듬, 템포, 화음, 곡 길이, 옥타브 등 | SNS, 댓글, 뉴스, 검색순위 등 |
- 데이터 수집 방법
- 음원 데이터 사이트 (음원 메타 데이터) : CIRCLE CHART, genie, 유튜브 뮤직 등
- 악보 데이터 사이트 (음원 자체 데이터) : 악보나라 등
- 소셜 데이터 사이트 (소셜 데이터) : 구글 트렌드 등
- 실습에서 사용된 데이터
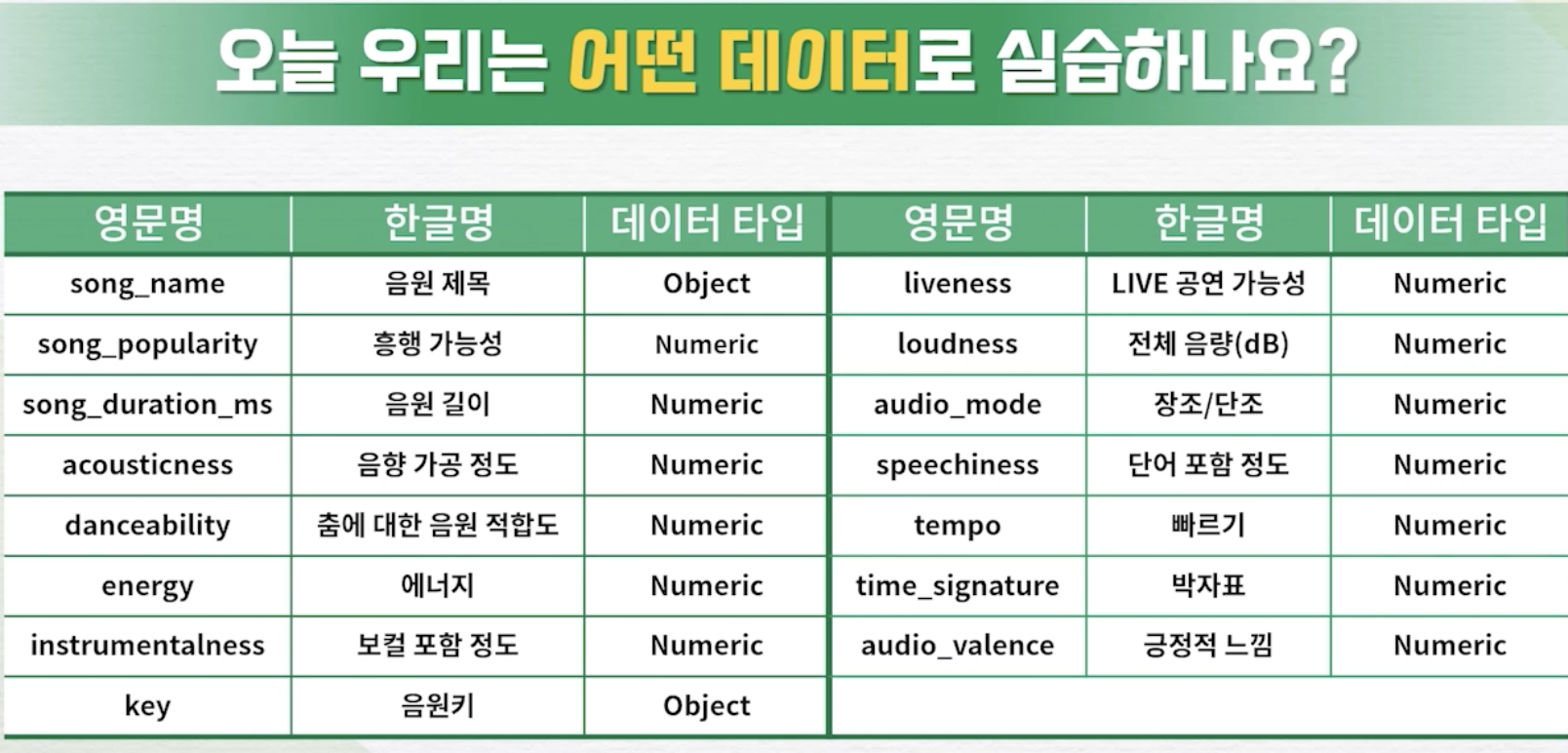
(데이터에 관한 자세한 설명은 생략)
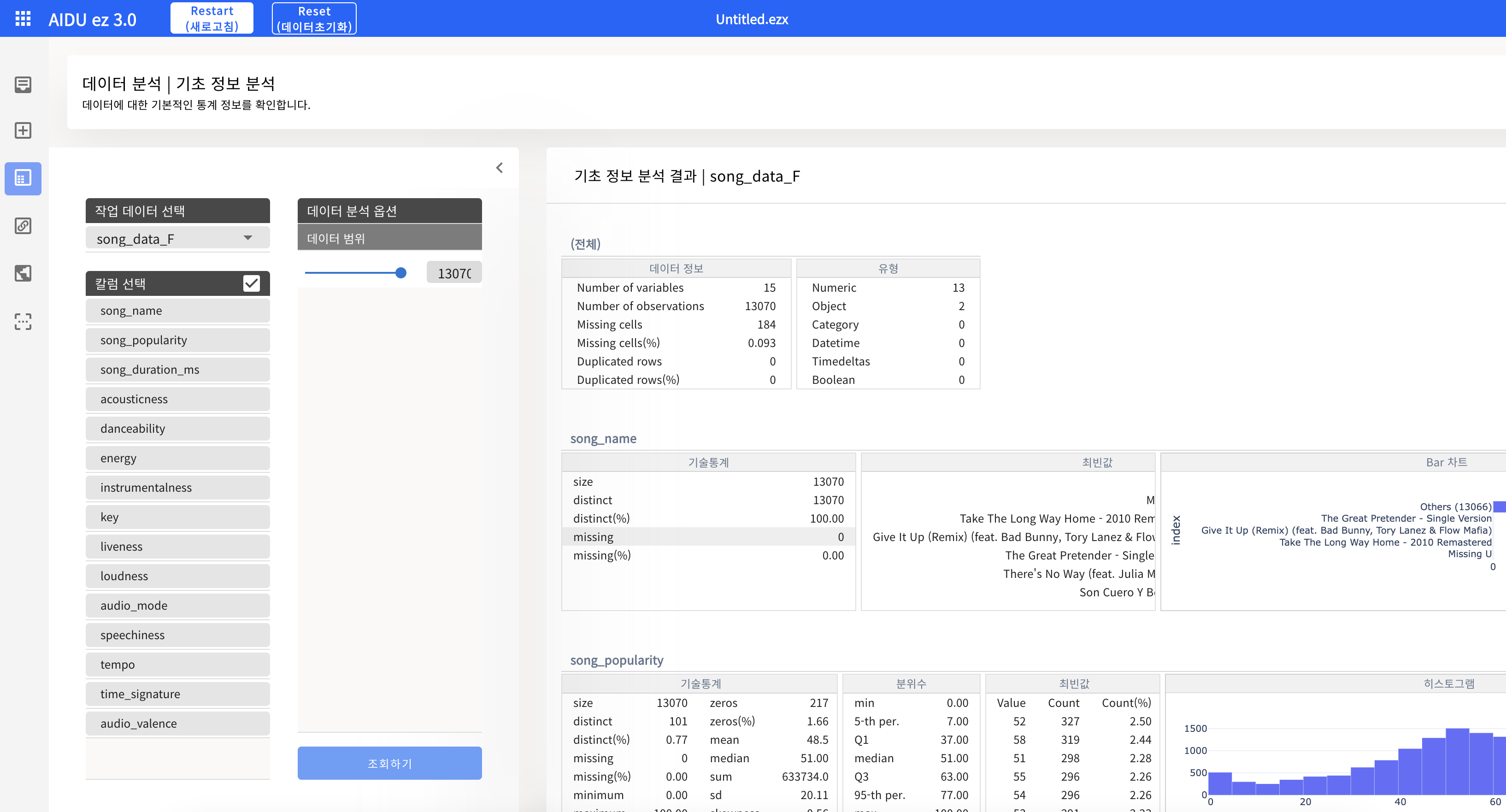
- AIDU ez를 활용한 데이터 확인 (기초 정보 분석)
- 데이터 가져오기 : song_data_F
- 데이터 분석 - 기초정보분석
3. 데이터 분석 및 전처리
- 데이터 시각화
- Feature 간 상관관계 분석 : Heat map
- Feature 자체 분석 : Box plot
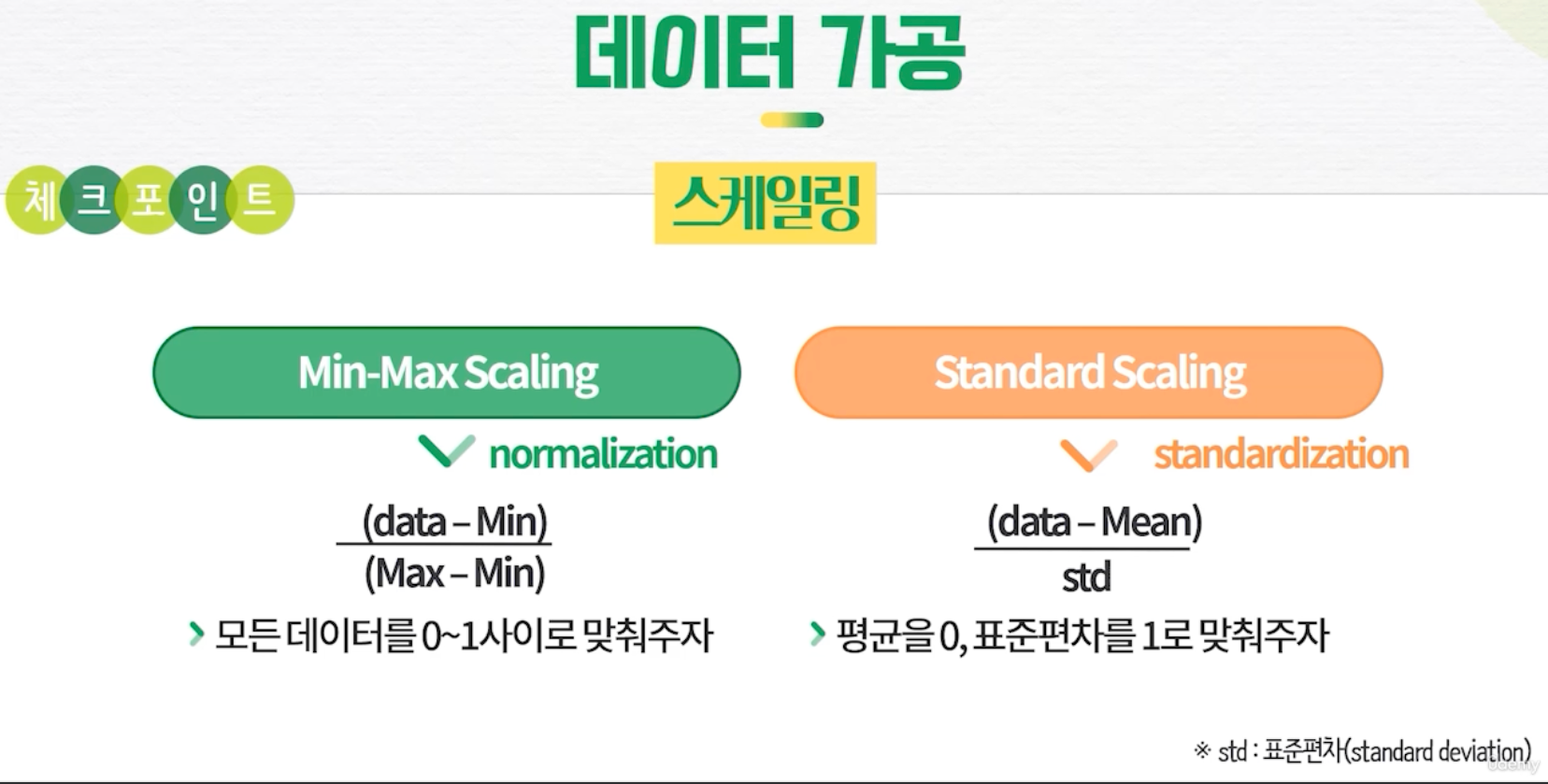
- 데이터 가공
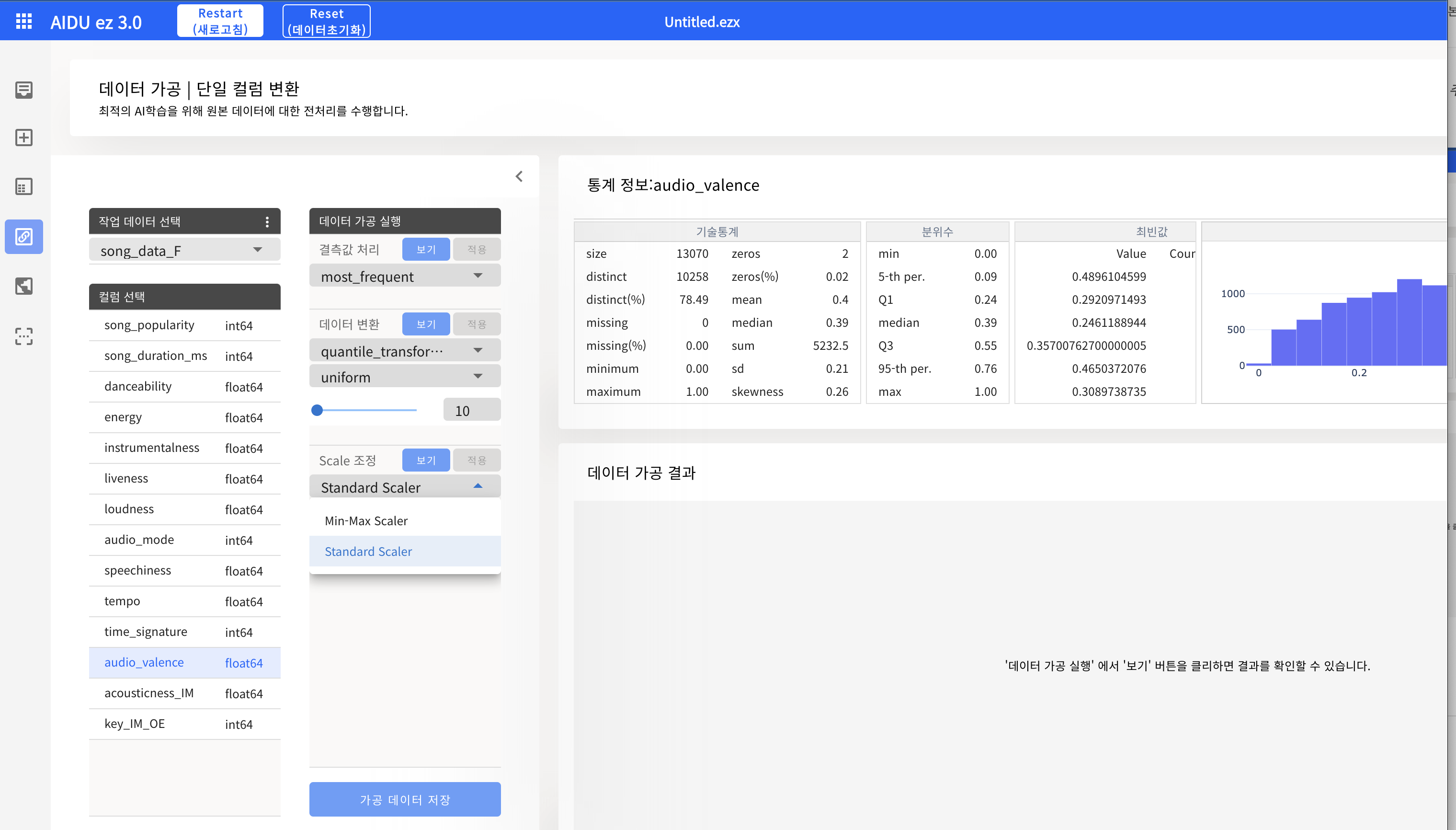
- 스케일링 : 수치형 데이터의 범위를 비슷하게 조정해 AI 모델이 적절히 학습할 수 있도록 함
- AIDU ez 제공 스케일러 : Min-Max Scaling, Standard Scaling
- 이상치 확인 및 제거 : 이상치 제거(이상치가 적을 경우) 또는 대체, 분류 모델의 경우 상황에 따라 이상치를 그대로 두기도 함
- 스케일링 : 수치형 데이터의 범위를 비슷하게 조정해 AI 모델이 적절히 학습할 수 있도록 함
AIDU ez를 활용한 데이터 분석 (시각화)
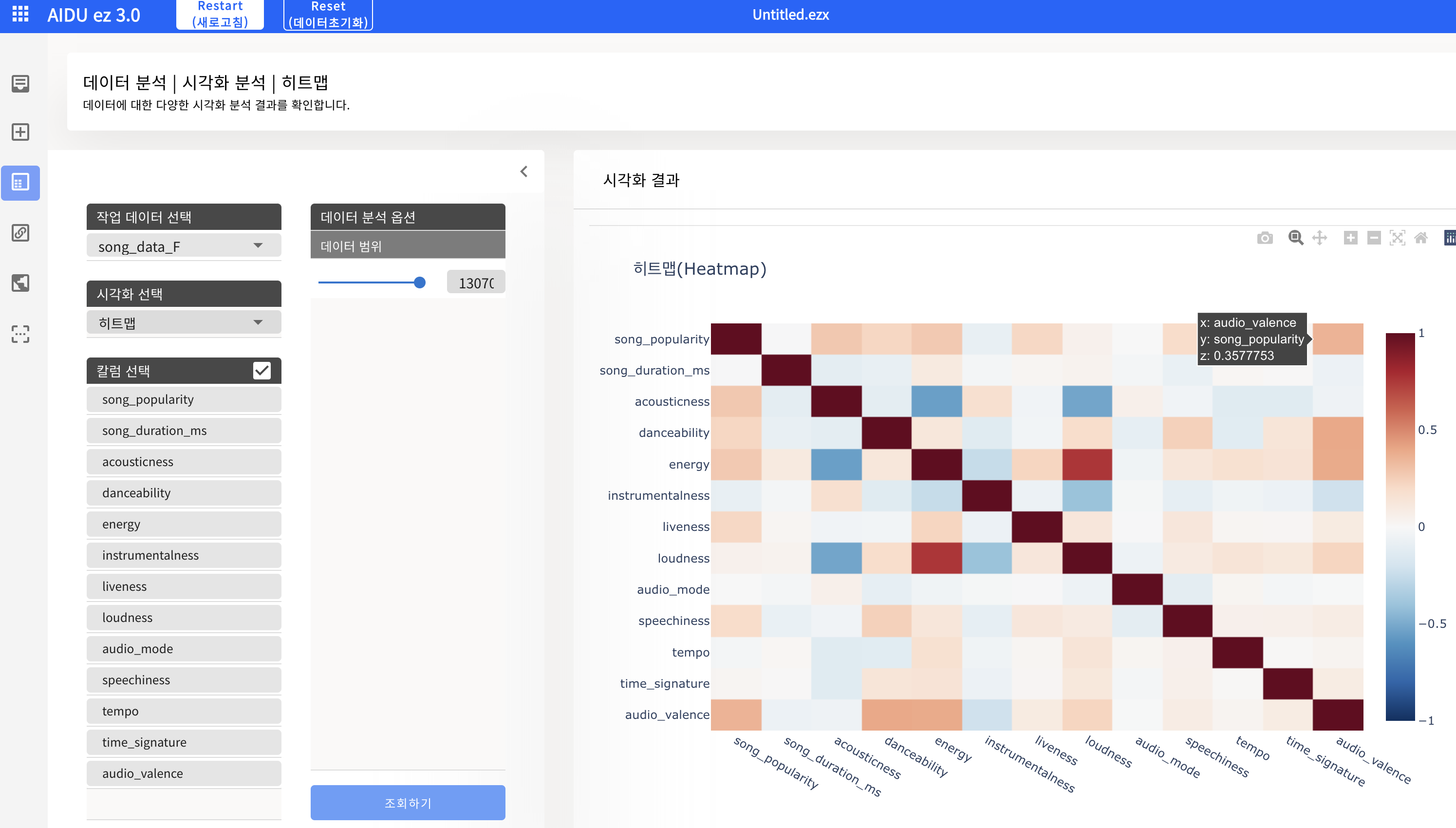
- 데이터 분석 - 시각화 - 히트맵
- 히트맵을 통한 feature 간 상관관계 분석하기 (인과관계가 아닌 상관관계임에 주의)
- 마우스를 통해 상관관계 값을 수치적으로 확인 가능
- 1행의 타겟 변수인 song_popularity와 상관 관계가 높은 feature : audio_valence, acousticness
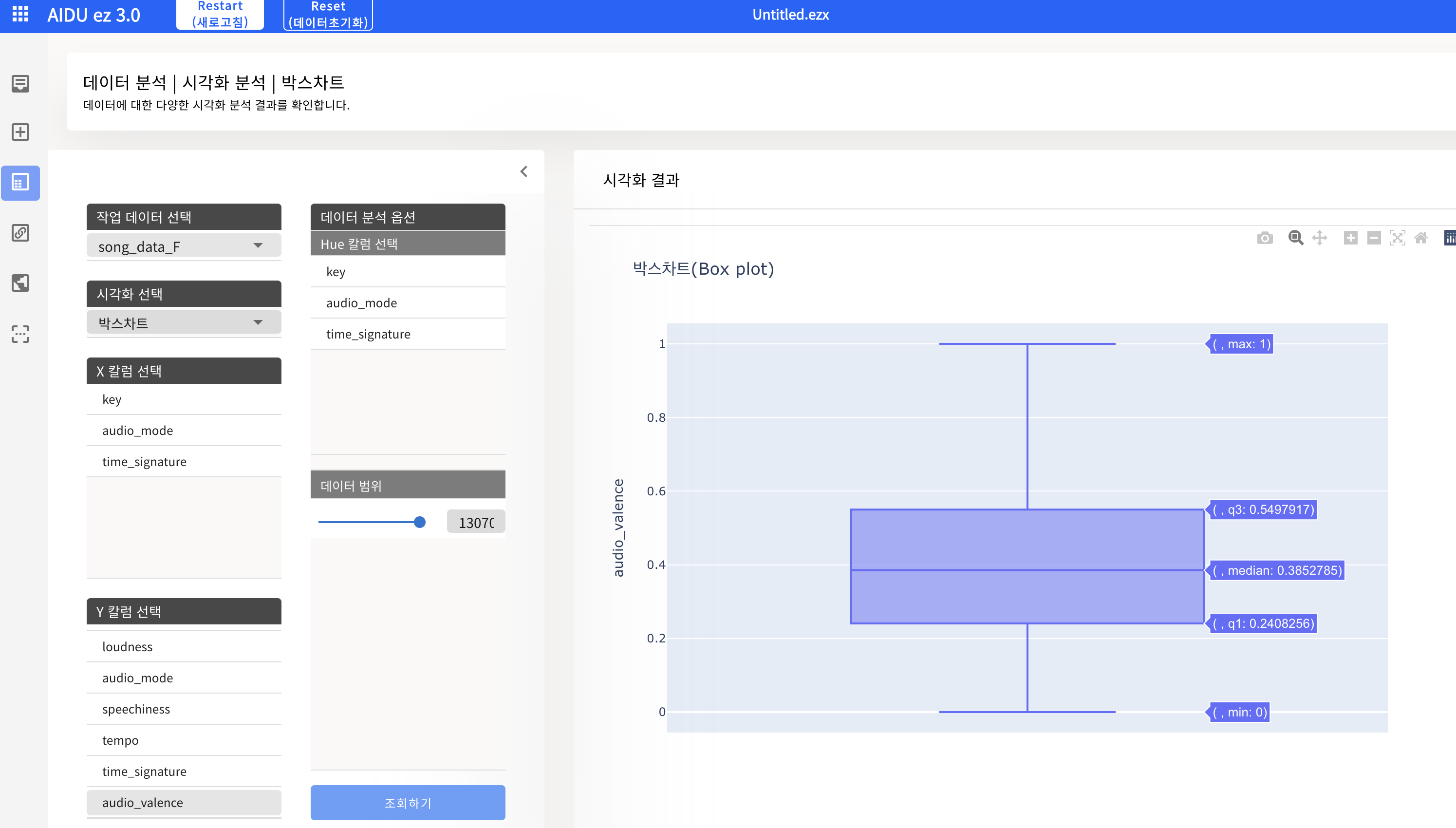
- 데이터 분석 - 시각화 - 박스차트
- 박스차트를 통한 feature 자체 분석하기 (데이터 분포, 이상치 등을 시각적으로 확인)
- 이상치 : Q3 + IQR * 1.5 이상 또는 Q1 - IQR * 1.5 이하 데이터 (IQR = Q3 - Q1)
- 이상치가 많은 경우, Standard Scaling 사용 권장
- 마우스를 통해 박스차트 구성 값을 수치적으로 확인 가능
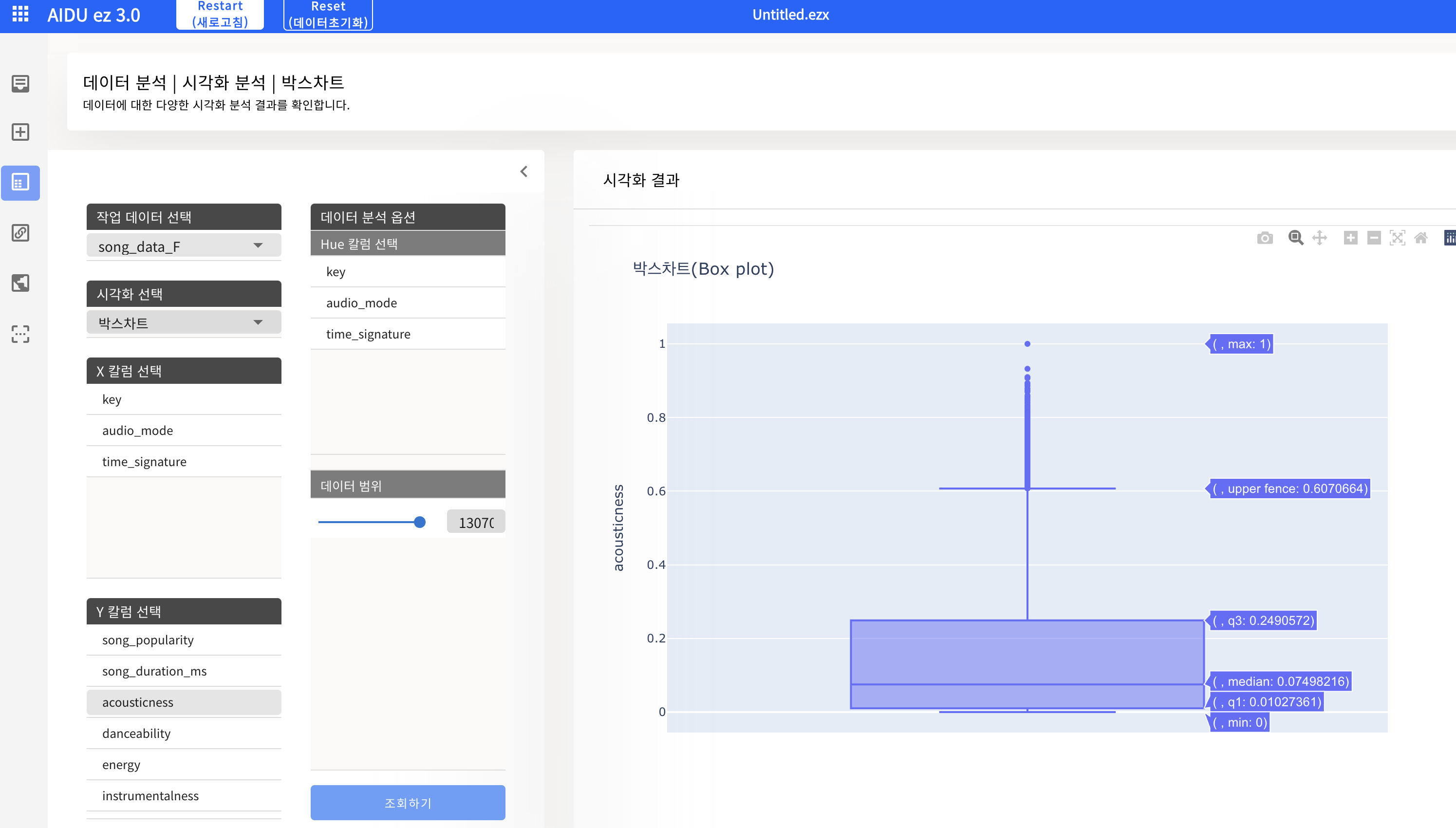
위의 두 컬럼에 대한 시각화 분석 후, 이상치가 없는 audio_valence는 Min-Max Scaling을, 이상치가 많은 acousticness는 Standard Scaling을 사용할 것으로 정할 수 있다.
AIDU ez를 활용한 데이터 분석 (통계 분석)
- 타겟 변수의 종류 확인 : 데이터 전처리의 방향성 및 AI 모델 결정

(회귀 모델 실습인 것을 이미 알고 있지만, 모를 경우 기초 정보 분석을 통해 어떤 식으로 데이터를 처리하고 어떤 AI 모델을 선택할지 결정)
- AI 모델 학습에 무의미한 Feature 제외
- distinct 값은 중복된 값을 제외한 데이터의 비율, 100%인 경우는 인덱스와 다를 것이 없으므로 학습에 무의미
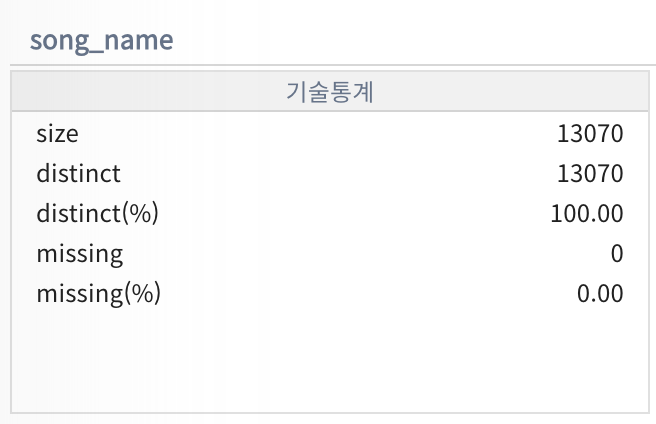
- 결측치 처리
- 결측치가 포함된 행 또는 Feature 삭제 (학습 데이터가 부족한 경우 대체를 권장)
- 결측치를 대푯값으로 대체 : 수치형(평균/중앙값 : 극단적인 이상치가 있는 경우 중앙값 권장), 범주형(최빈값)

(acousticness는 극단적인 이상치가 많으므로 중앙값으로 결측치를 대체하는 것이 좋다)
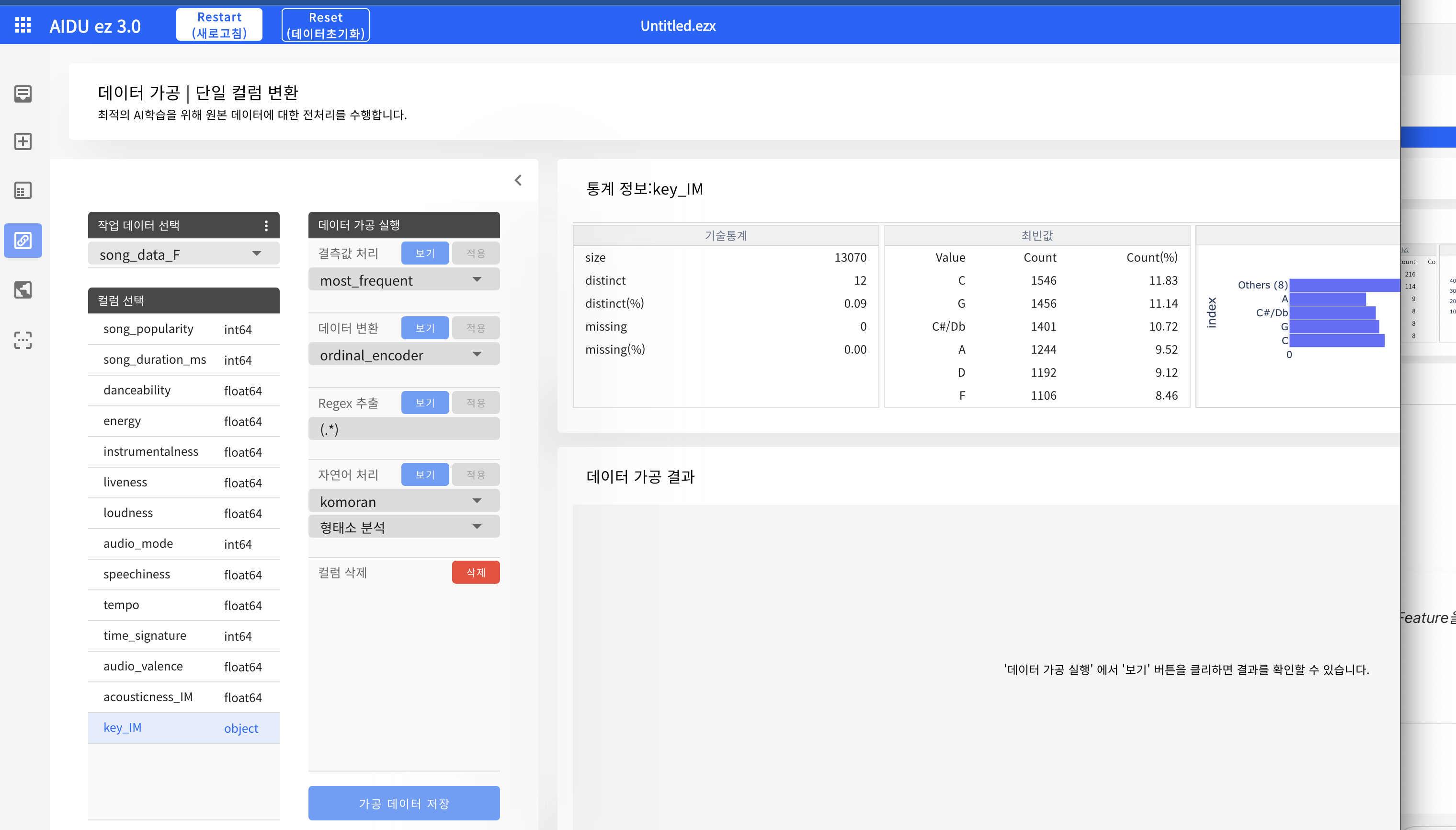
- 인코딩
- One-Hot Encoding : 순서가 무의미한 범주형 Feature에 적용
- Original Encoding : 순서가 유의미한 범주형 Feature에 적용
AIDU ez를 활용한 데이터 전처리
- 데이터 분석을 통해 얻은 인사이트를 바탕으로 데이터 전처리를 진행
- 학습할 Feature 선택 (무의미한 Feature 삭제)
- 결측치 처리 (반드시 인코딩 및 스케일링 전에 처리할 것)
- 인코딩 / 스케일링
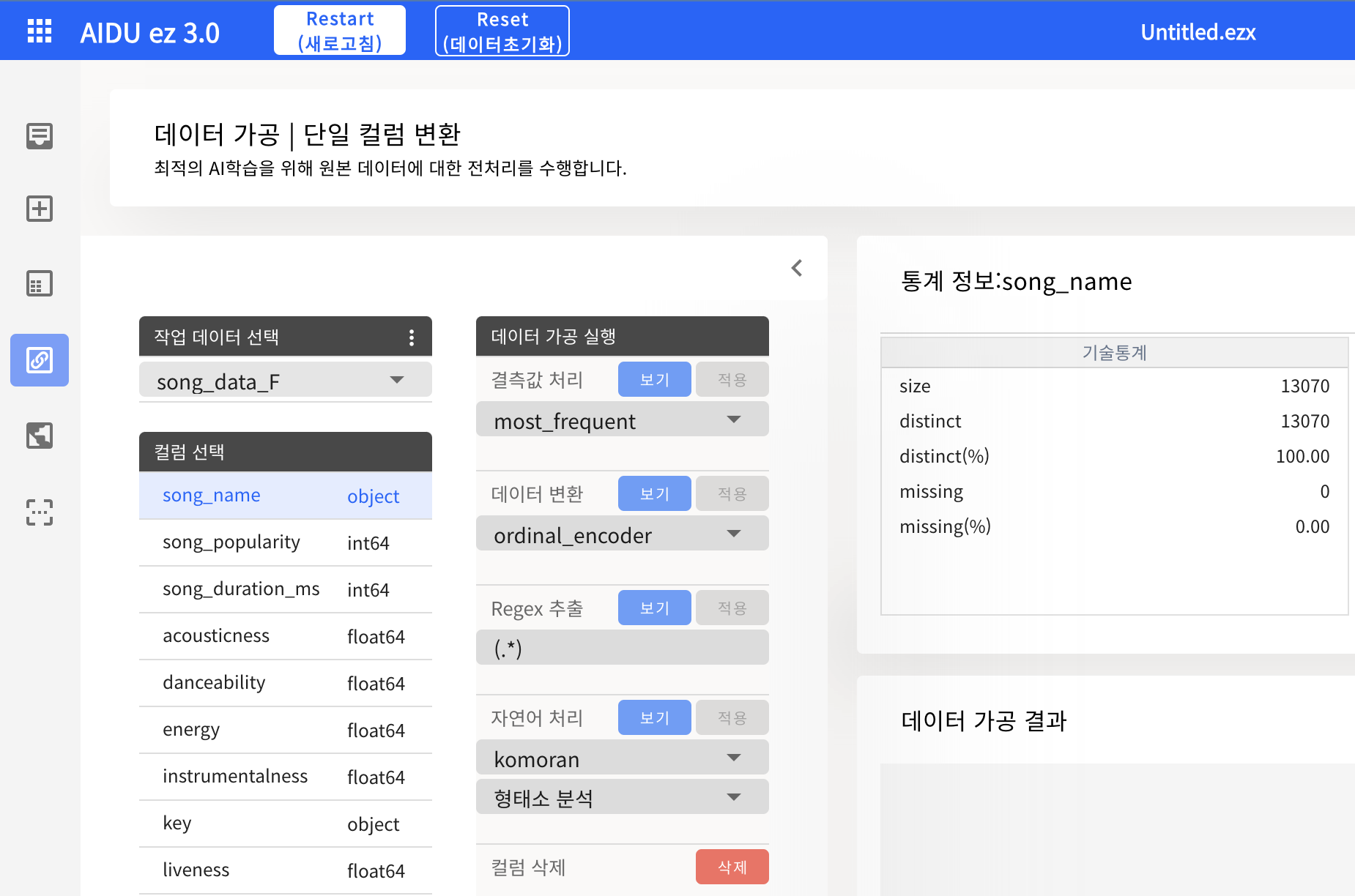
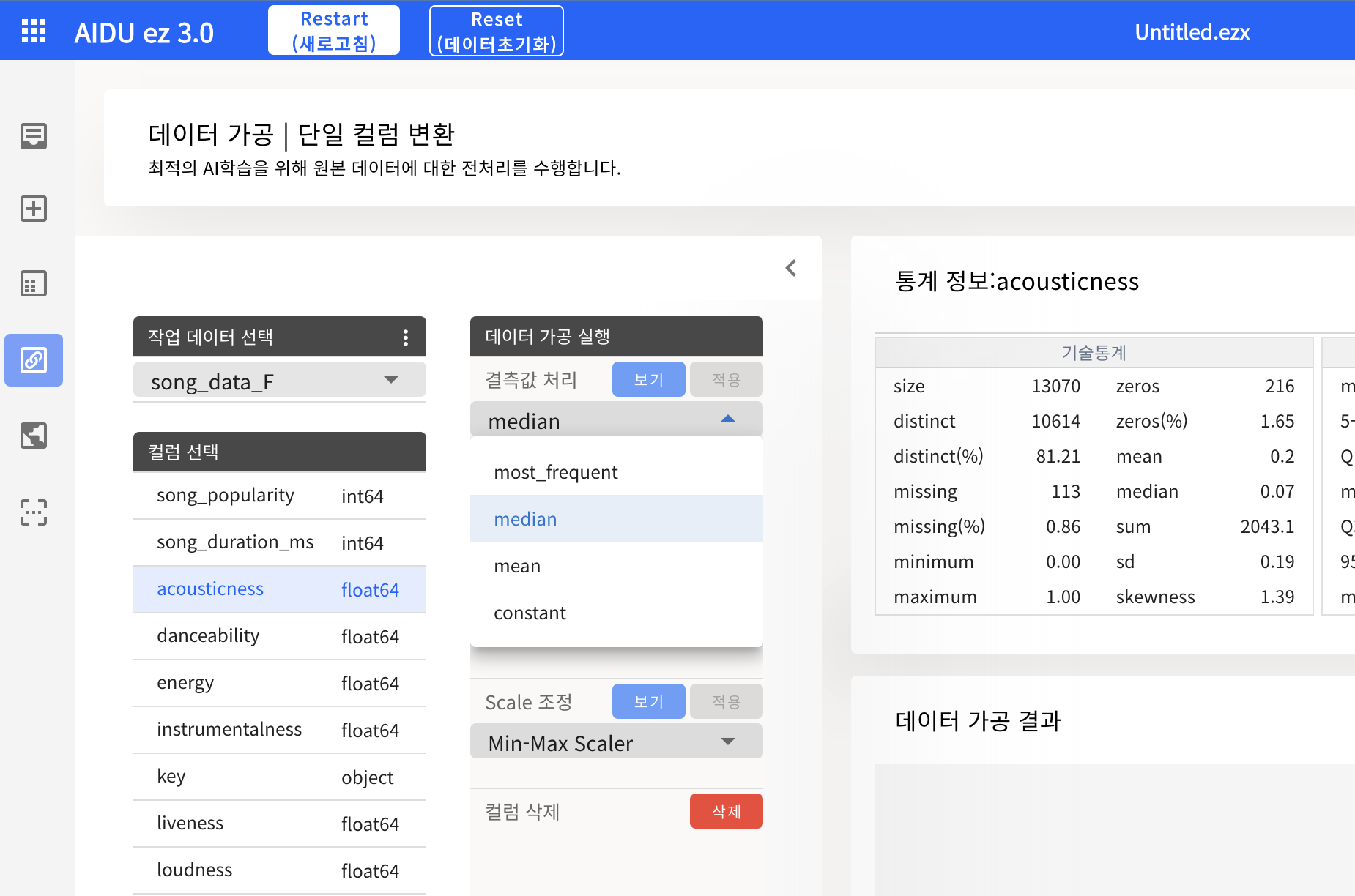
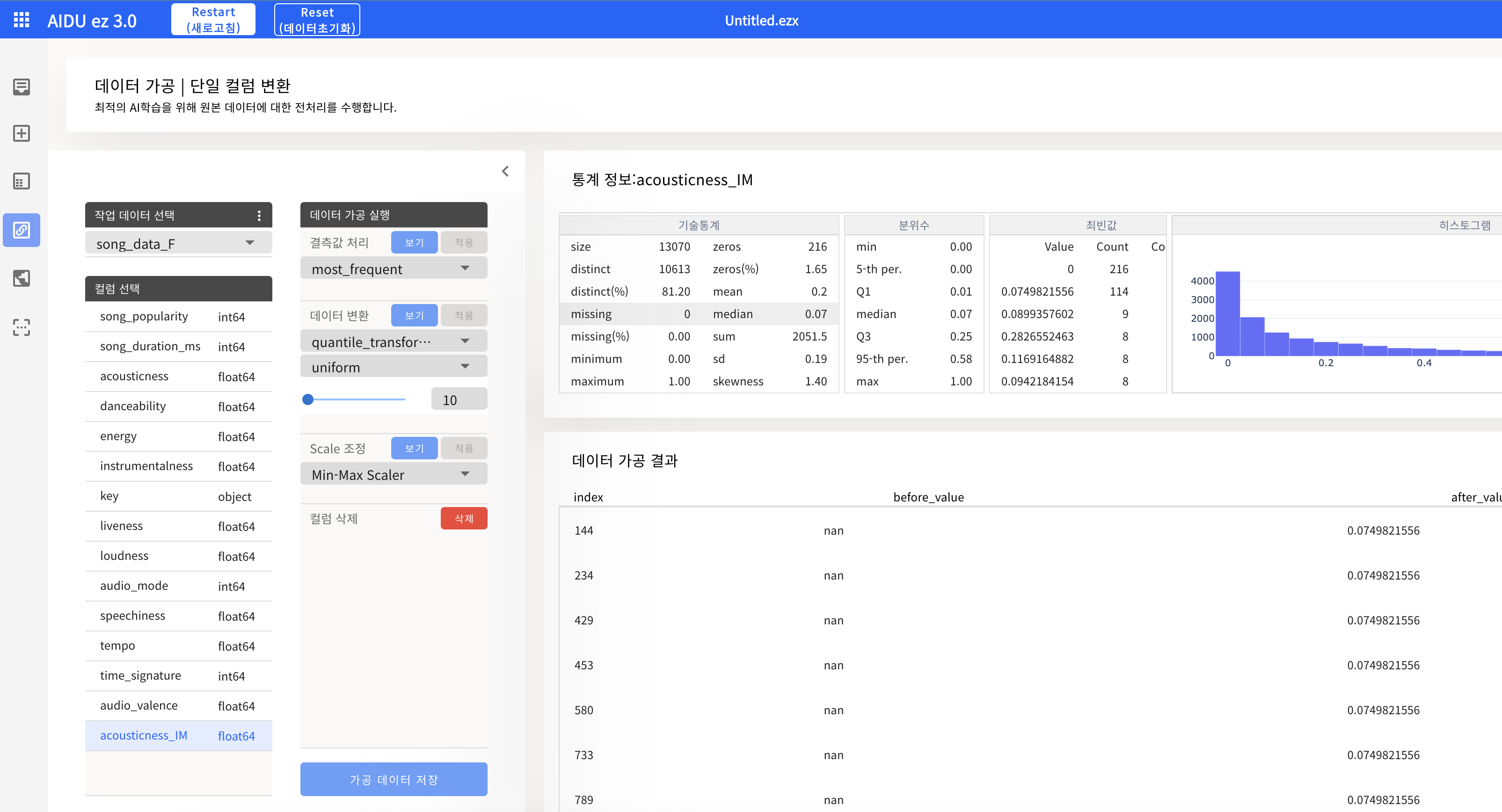
(AIDU ez에서 데이터 가공을 할 경우, 원본 Feature을 변경하는 것이 아니라, 원본을 가공한 새로운 Feature을 추가하므로, 데이터를 가공한 후 원본 acousticness Feature을 삭제하면 된다.)
- 모든 데이터에 대해 적절히 전처리를 한 경우 하단의 가공 데이터 저장을 통해 진행사항을 저장하고 AI 모델링으로 넘어갈 수 있다.
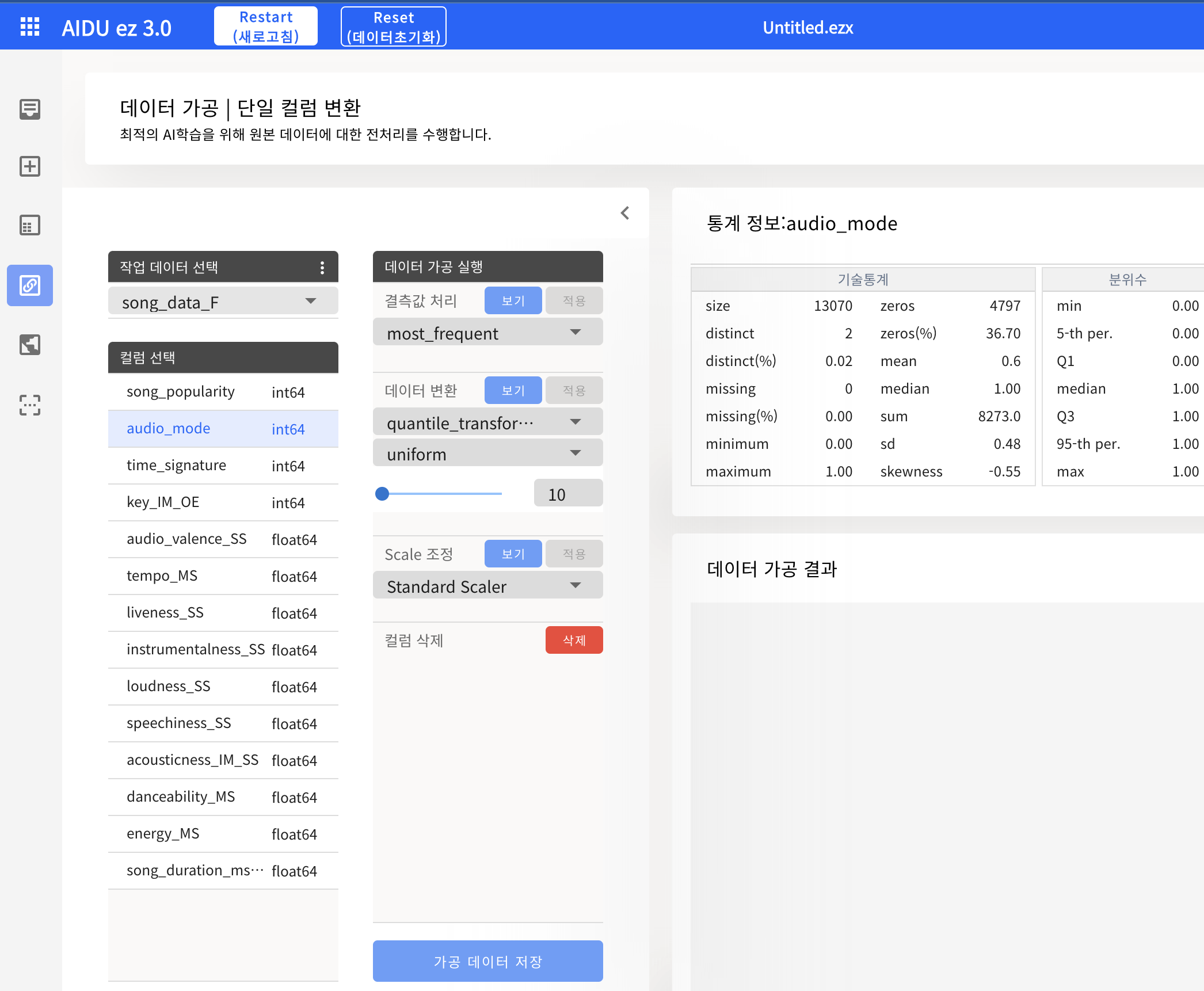
4. AI 모델링
- AI 회귀 모델 성능평가 지표
- MSE(Mean Squared Error) : "실제값 - 예측값"의 제곱의 평균 [작을수록 좋음]
- MAE(Mean Absolute Error) : "실제값 - 예측값"의 절댓값의 평균 [작을수록 좋음]
- R2(결정계수) : 독립변수가 종속변수를 얼마나 잘 설명하는가 [1에 가까울수록 좋음, 음수일 경우 모델 사용 불가]
- AI 모델 학습
- 전처리 완료한 작업 데이터 선택
- 타겟 변수인 song_popularity를 Output 컬럼으로 이동 (화살표 버튼 클릭)
- 학습 유형을 Regression으로 변경
- 모델 및 파라미터 설정
- 학습을 완료한 후에는 모델을 저장 (캡처본에는 짤려있지만 드래그를 통해 오른쪽 상단으로 가면 모델 저장 버튼이 있음)
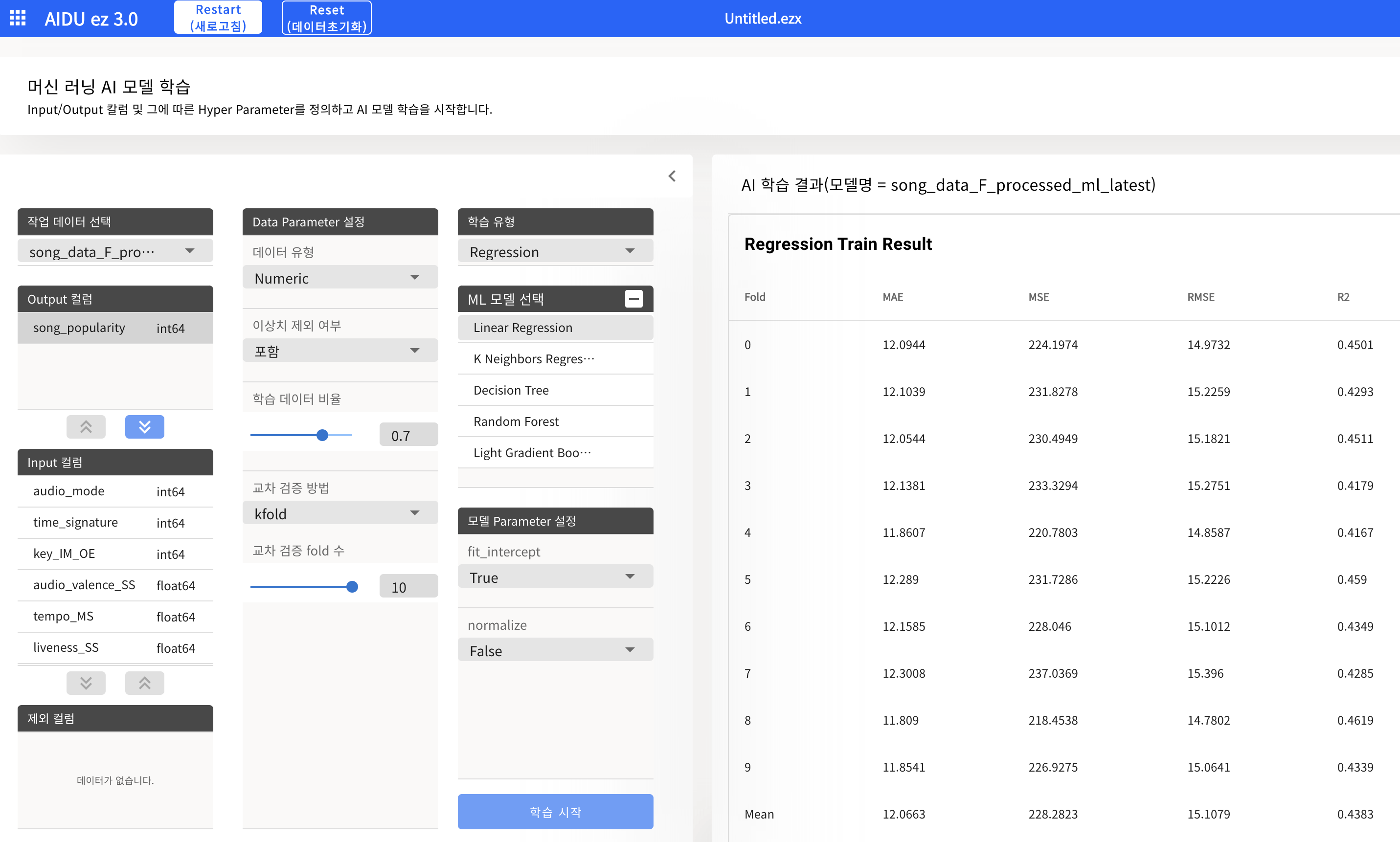
- AI 모델 성능 비교
- 직접 4개의 AI 모델을 돌리며 성능평가를 확인한 결과, 설명력이 높으며 오차가 적절히 적은 Random Forest가 제일 이상적
| AI 모델 | MAE | MSE | R2 |
| Linear Regression(ML) | 12.06 | 228.28 | 0.43 |
| Decision Tree(ML) | 12.64 | 291.27 | 0.28 |
| Random Forest(ML) | 9.02 | 141.56 | 0.65 |
| DNN(DL) | 0.66 | 0.76 | 0.17 |
- AI 모델의 성능을 높이는 방법
- 더 많은 수의 학습 데이터를 사용
- AI 모델 알고리즘 변경
- 피처엔지니어링을 통한 파생 변수 생성
- AI 모델 알고리즘의 하이퍼파라미터 변경
5. AI 적용
- AIDU ez는 저장한 AI 모델을 바탕으로 다음 기능을 제공한다.
- 분석하기
- 변수 영향도 확인
- 시뮬레이션
- 예측하기
- 다운로드
- 삭제하기
주의사항 : AICE basic 시험 시 모델을 평가하는 데이터가 우리가 전처리한 것처럼 처리되지 않은 데이터로 평가하는 경우, 평가를 제대로 할 수 없거나 낮은 점수를 받을 수 있다. 따라서 시험에서 모델을 평가하는 데이터 기준에 맞춰 전처리를 진행해야 한다. 위의 실습에서 진행한 스케일링된 데이터로 학습한 AI모델을, 시험 평가 시 스케일링 안된 데이터로 평가하는 경우 제대로 된 평가를 받을 수 없다.
그러므로 평가 데이터에 대한 별다른 사항이 없다면 전처리는 어디까지나 데이터를 분석하는 것에만 사용하며 원본을 변경하는 것은 결측치 채우기만을 하는 것이 좋을 수 있다.
'대외활동 > AICE대학생 서포터즈' 카테고리의 다른 글
| [AICE 자격증] AICE Basic 시험 성적 & 오픈배지 (0) | 2024.04.08 |
|---|---|
| [AICE 자격증] AICE Basic 시험 후기 및 팁 (2) | 2024.03.16 |
| [AICE 자격증] AIDU ez 실습 [분류] : 중공업 선박 수주 여부 예측 (7일차) (1) | 2024.03.14 |
| [AICE 자격증] AIDU ez 실습 [분류] : 항공사 고객 만족 여부 예측 (6일차) (0) | 2024.03.14 |
| [AICE 자격증] AI 구현 프로세스_2 (4일차) (0) | 2024.03.07 |
| [AICE 자격증] AI 구현 프로세스_1 (3일차) (0) | 2024.03.06 |
| [AICE 자격증] 노코딩 AIDU ez 활용법 (2일차) (0) | 2024.03.06 |
| [AICE 자격증] AI의 이해 (1일차) (1) | 2024.03.04 |



